📝 Paper Summary
Causal Discovery
Large Language Models
Counterfactual Reasoning
LLMs can act as domain experts to generate accurate causal graphs and support counterfactual reasoning, significantly outperforming traditional covariance-based discovery algorithms by leveraging metadata rather than data values.
Core Problem
Traditional causal discovery algorithms rely on statistical patterns in data but struggle to capture domain knowledge, often resulting in inaccurate causal graphs. Conversely, manual specification by experts is labor-intensive.
Why it matters:
- Correct causal reasoning is essential for critical domains like medicine, law, and policy to avoid disastrous decision-making based on mere correlation.
- Capturing domain knowledge in formal representations is a primary bottleneck for widespread adoption of causal methods.
- Existing statistical methods (covariance-based) often fail to distinguish directionality or unobserved confounders without strong assumptions.
Concrete Example:
In a medical diagnosis task (Tu et al., 2023), previous LLM attempts failed. However, this paper shows that with proper prompting, GPT-4 can correctly identify causal links (e.g., diseases causing symptoms) where statistical methods might only see correlations or infer incorrect directions due to data noise.
Key Novelty
LLMs as Metadata-Based Causal Reasoners
- Instead of analyzing numerical data rows (covariance), the LLM analyzes variable names and context (metadata) to infer causal structure based on internalized world knowledge.
- Combines LLM-generated causal graphs (logic/knowledge-based) with traditional token causality tasks (counterfactuals, necessary/sufficient causes) to bridge the gap between qualitative knowledge and formal causal inference.
Architecture
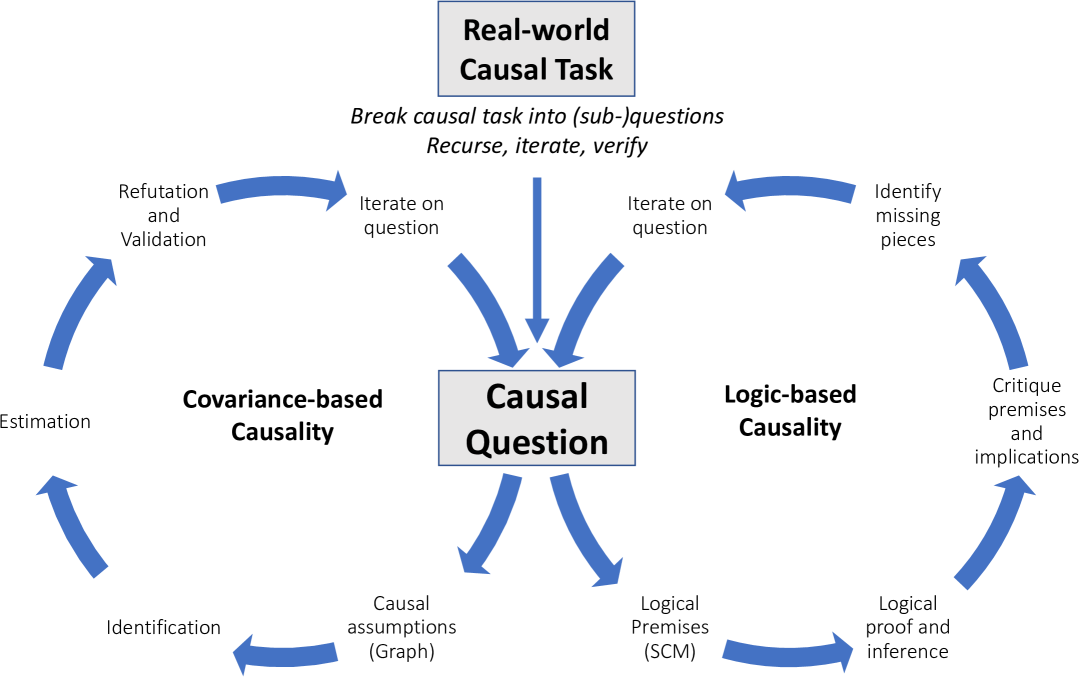
A conceptual framework illustrating how LLMs bridge different causal tasks (Covariance-based vs. Logic-based, Type vs. Token causality).
Evaluation Highlights
- GPT-4 achieves 97% accuracy on the Tübingen pairwise causal discovery benchmark, surpassing the previous best method (83%) by 14 points.
- GPT-4 scores 92% on a counterfactual reasoning benchmark (CRASS), a 20-point gain over previous best-performing methods.
- GPT-4 attains 86% accuracy in determining necessary and sufficient causes in vignettes, demonstrating strong token causality capabilities.
Breakthrough Assessment
8/10
Demonstrates a paradigm shift in causal discovery by using LLMs for metadata/knowledge processing rather than pure statistics, yielding state-of-the-art results on standard benchmarks.