📝 Paper Summary
Large Reasoning Models (LRMs)
Chain-of-Thought (CoT) Compression
Efficient Inference
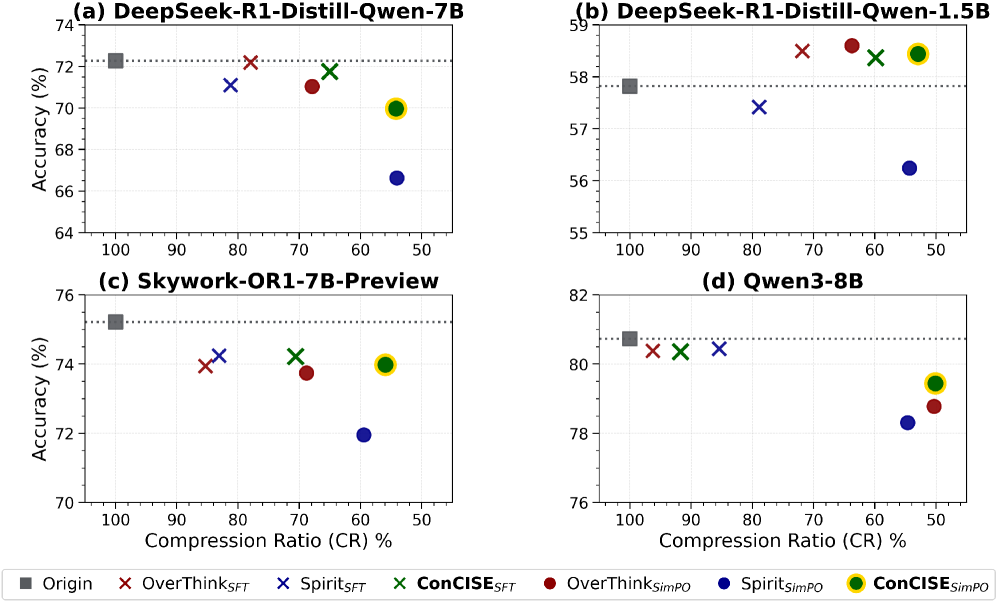
ConCISE constructs concise training data by injecting confidence phrases to suppress redundant self-corrections and using early stopping to truncate post-answer verification, enabling smaller, faster reasoning models without accuracy loss.
Core Problem
Large Reasoning Models generate excessively verbose Chain-of-Thought outputs, increasing computational costs. Existing compression methods like sampling or pruning either fail to remove all redundancy or disrupt reasoning coherence.
Why it matters:
- LRMs like OpenAI-o1 and DeepSeek-R1 incur high inference costs due to long reasoning chains
- Sampling-based compression lacks control during generation, leaving unnecessary steps
- Post-hoc pruning breaks the logical flow of reasoning, degrading model performance after fine-tuning
Concrete Example:
An LRM might correctly solve a math problem but then spend multiple steps explicitly verifying the answer despite high internal confidence ('Wait, let me double check...'), or it might doubt a correct intermediate step ('Is this correct? Let me re-calculate'), adding zero semantic value.
Key Novelty
Confidence-guided Compression in Step-by-step Efficient Reasoning (ConCISE)
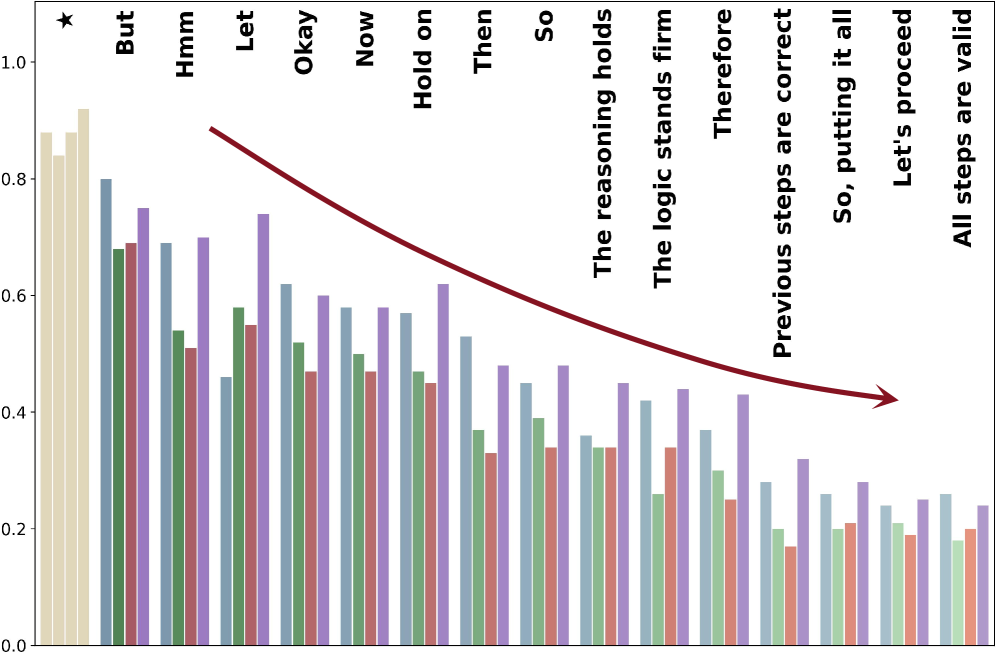
- Identifies 'Confidence Deficit' (doubting correct steps) and 'Termination Delay' (continuing after solving) as key redundancy sources linked to internal confidence levels
- Uses 'Confidence Injection' to artificially boost model confidence before potential reflection points, suppressing unnecessary self-correction steps during data generation
- Employs 'Early Stopping' with a lightweight confidence detector to halt generation immediately after the model is statistically certain of its answer
Architecture
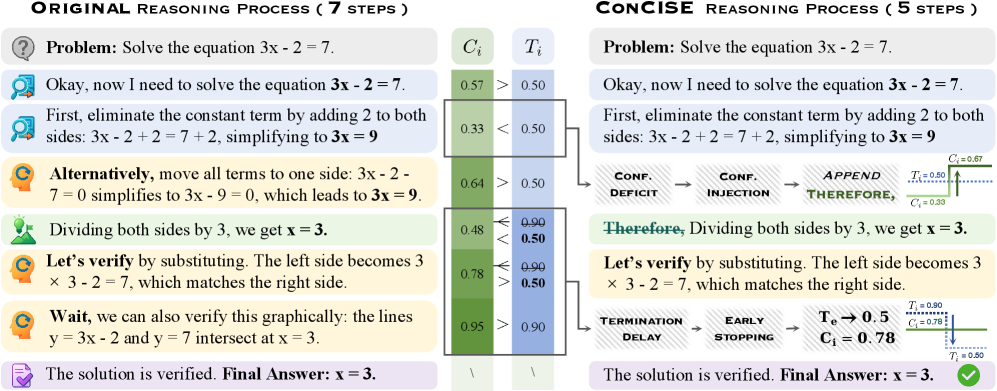
The ConCISE data construction pipeline.
Evaluation Highlights
- Reduces average response length by ~50% under SimPO fine-tuning compared to original baselines while maintaining high accuracy
- Outperforms standard SFT and DPO baselines on math and logic benchmarks (MATH, GSM8K, LogicStruct)
- Achieves superior trade-off between token reduction and task performance compared to sampling-based and pruning-based compression methods
Breakthrough Assessment
8/10
Offers a novel, theoretically grounded perspective (confidence dynamics) on CoT redundancy. effectively solving the trade-off between brevity and accuracy where previous pruning methods failed.