📊 Experiments & Results
Evaluation Setup
Unsupervised adaptation on test sets (using the test set for 'training' without labels, then evaluating)
Benchmarks:
- GSM8K (Grade-school math word problems)
- MATH500 (Competition math problems)
- AMC (High school math competition (AMC12))
- AIME24 (Advanced invitational math exam)
- GPQA (PhD-level science QA)
Metrics:
- Accuracy
- Entropy / Confidence
- Statistical methodology: Standard deviations reported over multiple samples (5, 32, 64, 10 depending on dataset)
Experiment Figures
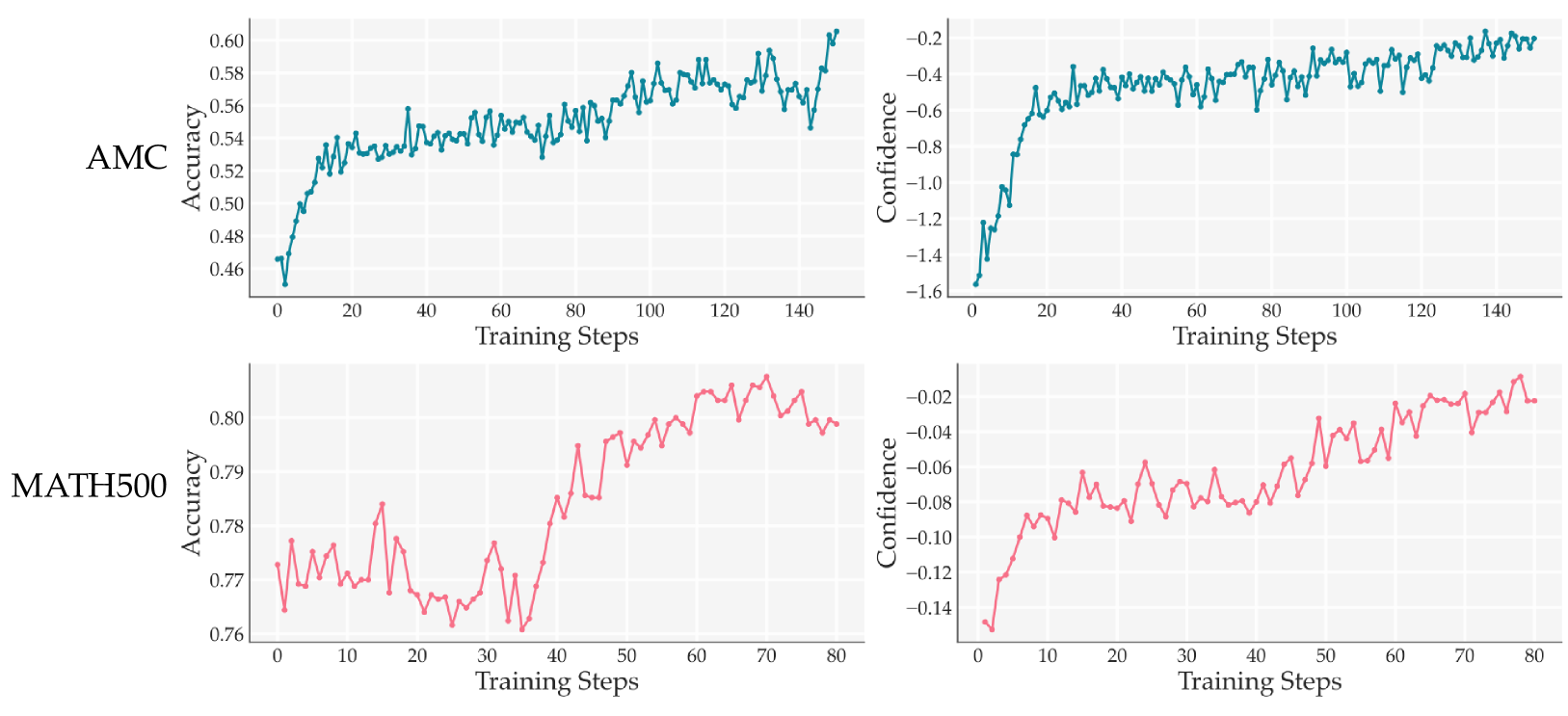
Plots of accuracy and confidence throughout training for Qwen2.5-Math-7B (AMC) and Qwen2.5-7B-Instruct (MATH500)
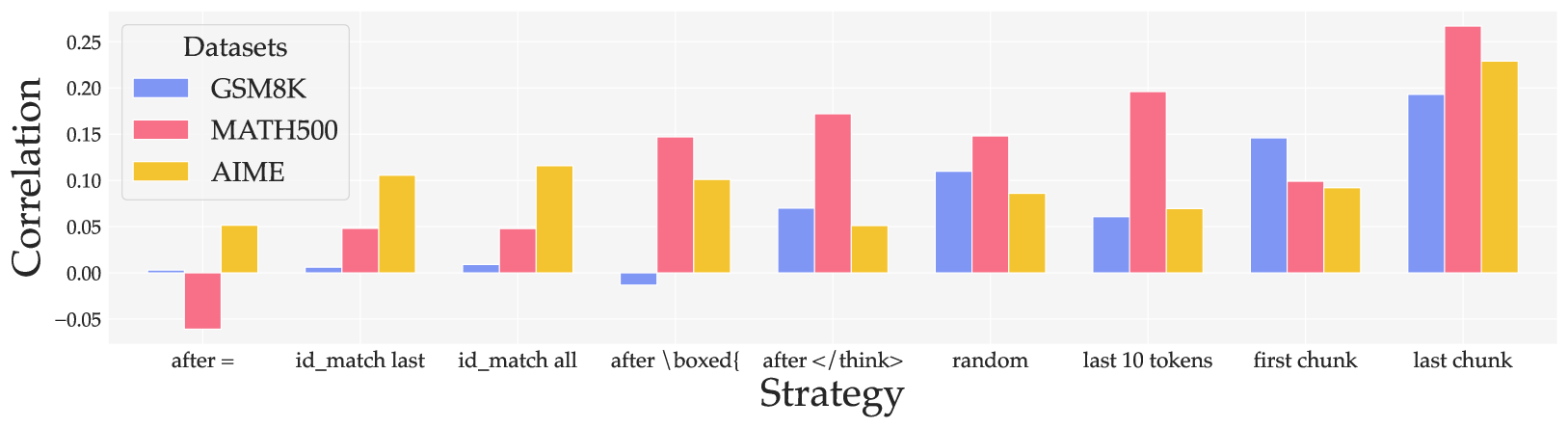
Correlation between negative entropy and accuracy for different token selection strategies
Main Takeaways
- Minimizing entropy via RL (RENT) consistently improves reasoning accuracy across diverse math and science benchmarks without ground-truth supervision.
- The 'last chunk' of tokens in a chain-of-thought response contains the most valuable confidence signal; minimizing entropy here correlates strongly with accuracy.
- Surprisingly, minimizing entropy specifically on the final answer tokens (id_match) is less effective, suggesting the model's token-level confidence on the final output symbol is not well-calibrated.
- RENT outperforms baseline unsupervised methods including Format Reward (syntax only), Spurious (random) rewards, and Test-Time RL (majority voting), particularly on harder tasks like AIME.
- Generalization holds across different model families (Qwen, Mistral, Llama) and sizes, indicating the method is model-agnostic.