📝 Paper Summary
Chain-of-Thought Prompting
Zero-shot Reasoning
Plan-and-Solve Prompting improves zero-shot reasoning by explicitly instructing LLMs to devise a plan and execute it, replacing simple step-by-step triggers.
Core Problem
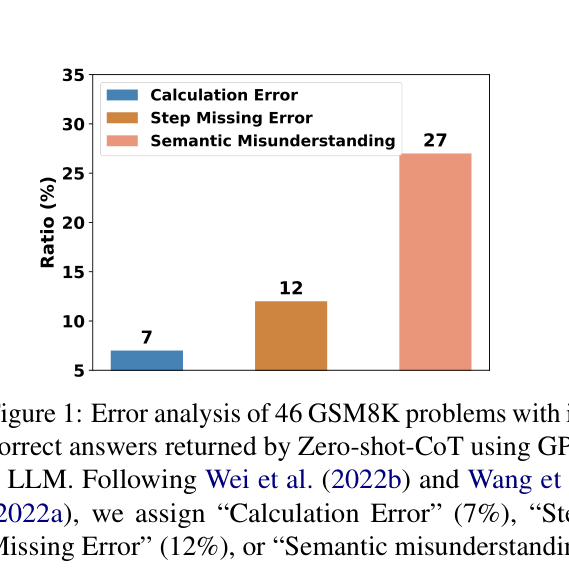
Zero-shot Chain-of-Thought (CoT) prompting often fails on complex tasks due to calculation errors, missing reasoning steps, and semantic misunderstandings.
Why it matters:
- Large Language Models (LLMs) are often deployed as services without access to parameters for fine-tuning, making effective zero-shot prompting crucial
- Manual few-shot prompting requires labor-intensive crafting of demonstrations, which zero-shot approaches aim to eliminate
- Existing zero-shot triggers like 'Let's think step by step' are insufficient for preventing logic gaps in multi-step problems
Concrete Example:
In a math problem asking for the combined weight of Grace and Alex, Zero-shot-CoT might attempt to add numbers immediately and miss the intermediate step of calculating Alex's weight first. Plan-and-Solve explicitly generates a plan: '1. Find Grace's weight... 2. Find Alex's weight... 3. Sum them', preventing the missing step.
Key Novelty
Plan-and-Solve (PS) Prompting
- Replaces the generic 'Let's think step by step' trigger with a two-stage instruction: first devise a plan to decompose the task, then execute the plan
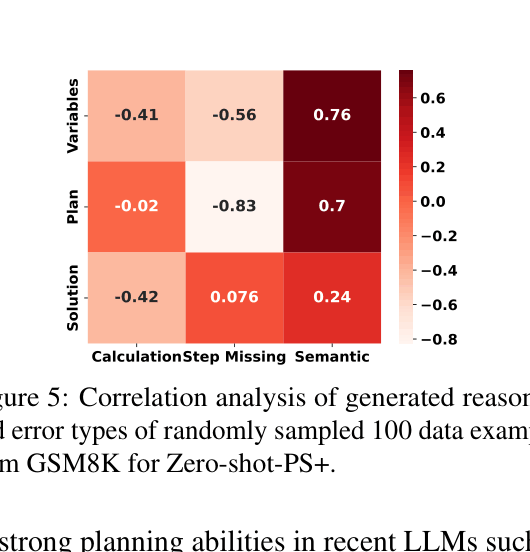
- Extends this with PS+ prompting, which adds detailed instructions to extract variables and pay attention to calculations, effectively guiding the model to avoid specific error types like missing variables or arithmetic mistakes
Architecture
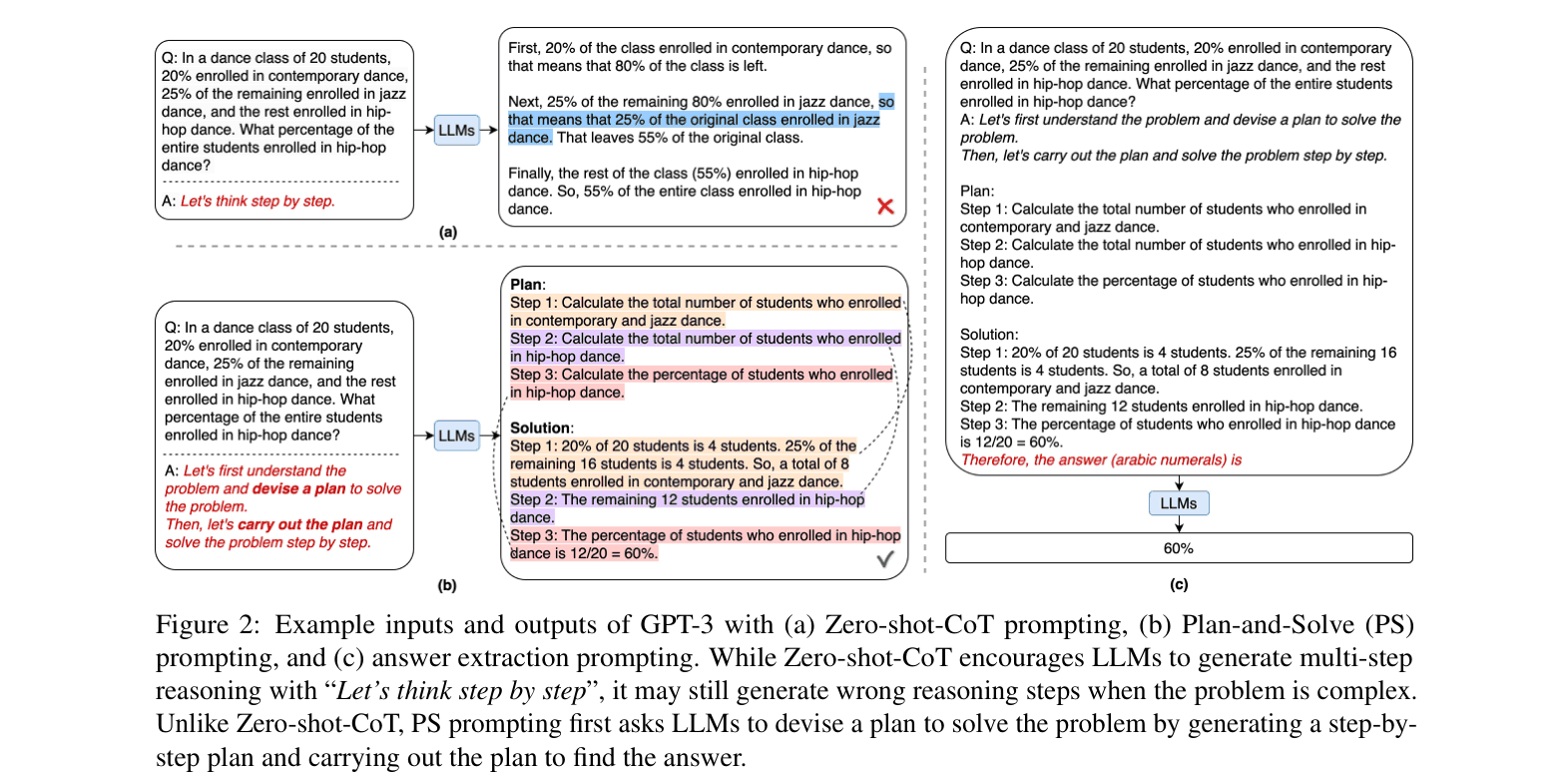
Comparison of Zero-shot-CoT vs. Plan-and-Solve (PS) Prompting workflows
Evaluation Highlights
- PS+ prompting achieves 76.7% average accuracy across six arithmetic datasets, surpassing Zero-shot-CoT (70.4%) and Zero-shot-Program-of-Thought (73.5%)
- On CommonsenseQA, PS+ prompting scores 71.9%, significantly outperforming Zero-shot-CoT (65.2%)
- Matches the performance of 8-shot Manual-CoT (77.6% average on math) without requiring any manual demonstration examples
Breakthrough Assessment
7/10
Simple yet highly effective prompting strategy that significantly closes the gap between zero-shot and few-shot performance, addressing specific reasoning failure modes.