📝 Paper Summary
Multimodal Emotion Recognition
Multimodal Large Language Models (MLLMs)
Affective Computing
Emotion-LLaMA integrates audio and multi-view visual features into a large language model via instruction tuning on a newly constructed diverse multimodal dataset to achieve state-of-the-art emotional recognition and reasoning.
Core Problem
Existing Multimodal Large Language Models (MLLMs) like GPT-4V struggle with emotion recognition because they lack audio integration (critical for vocal tones) and fail to detect subtle facial micro-expressions.
Why it matters:
- Accurate emotion perception is essential for human-computer interaction, education, and psychological counseling, where missing subtle cues leads to failure
- Real-world emotional data is inherently multimodal (text, audio, video), but current models often rely on single modalities or simple feature fusion without deep reasoning capabilities
- There is a scarcity of specialized multimodal emotion instruction datasets, limiting the ability of large models to learn complex emotional reasoning
Concrete Example:
A user might sarcastically say 'Great job' with a frowning face and flat tone. A standard vision-only model sees the text 'Great job' and might classify it as positive, or miss the subtle frown. Emotion-LLaMA integrates the flat audio tone and micro-expression visual features to correctly reason that the emotion is 'contempt' or 'doubt'.
Key Novelty
Emotion-LLaMA & MERR Dataset
- Creates MERR (Multimodal Emotion Recognition and Reasoning), a large-scale dataset with coarse and fine-grained annotations generated by a pipeline of specialized tools (OpenFace, Qwen-Audio, LLaMA-3) to teach models emotional context
- Aligns specific audio (HuBERT) and multi-view visual encoders (Spatial, Temporal, Global) into the LLaMA embedding space using trainable linear projections, allowing the LLM to 'sense' emotion directly
Architecture
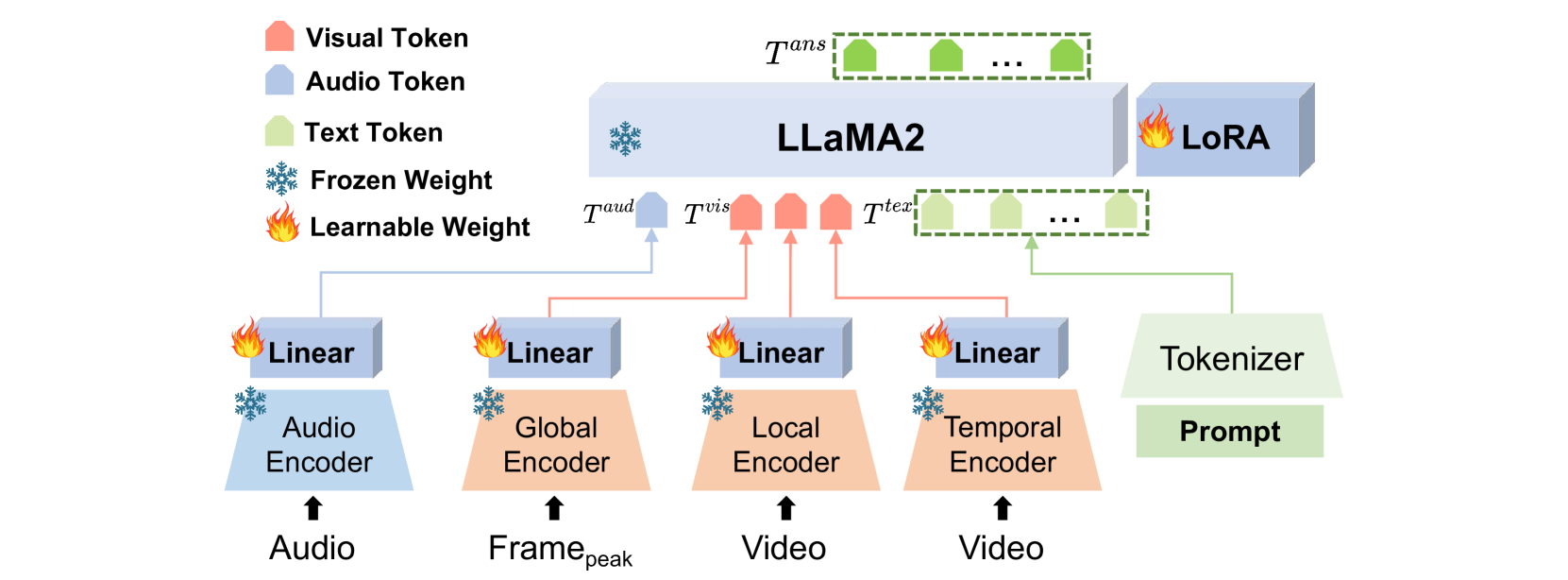
The architecture of Emotion-LLaMA, detailing the audio encoder, multi-view visual encoders, and their projection into the LLaMA model.
Evaluation Highlights
- Achieved top rank on the EMER challenge with a Clue Overlap score of 7.83 and Label Overlap of 6.25
- Surpassed ChatGPT-4V by +8.52% in zero-shot evaluation on the MER2024-OV dataset
- Obtained highest Unweighted Average Recall (UAR) of 45.59% on the DFEW dataset in zero-shot evaluations
Breakthrough Assessment
8/10
Significant contribution via the large-scale MERR dataset and a specialized architecture that outperforms generalist models like GPT-4V in specific emotion tasks. It effectively bridges the gap between general MLLMs and affective computing.