📝 Paper Summary
Video Understanding
Multimodal Large Language Models (MLLM)
Video-of-Thought enhances video reasoning by decomposing complex tasks into a chain of sub-problems, moving from fine-grained pixel-level grounding via scene graphs to high-level cognitive semantic analysis.
Core Problem
Existing video MLLMs struggle with complex videos due to two bottlenecks: a lack of fine-grained spatial-temporal perceptive understanding and an inability to perform deep cognitive-level reasoning.
Why it matters:
- Current methods mostly perform shallow perception on simple videos, failing to understand intricate spatiotemporal characteristics
- Complex real-world applications require understanding not just pixel movements but also the causal implications and commonsense reasoning behind actions
- Standard Chain-of-Thought prompting for language does not account for the specific spatiotemporal grounding needs of video data
Concrete Example:
In a video showing a person jumping from a height, a standard model might identify the action 'jumping', but fail to reason that this action implies a risk of fracture or requires specific medical attention, or fail to track the specific target 'red oil truck' before analyzing its interaction with a tanker.
Key Novelty
Video-of-Thought (VoT) Framework with MotionEpic MLLM
- Introduces MotionEpic, a video MLLM that incorporates Video Spatial-Temporal Scene Graphs (STSG) to achieve fine-grained pixel-level grounding
- Proposes VoT, a reasoning framework that breaks video QA into sequential steps: target identification, temporal grounding (via STSG), action analysis with commonsense, and answer verification
- Uses generated scene graphs as intermediate 'rationales' or evidence to ground the high-level reasoning in low-level video pixels
Architecture
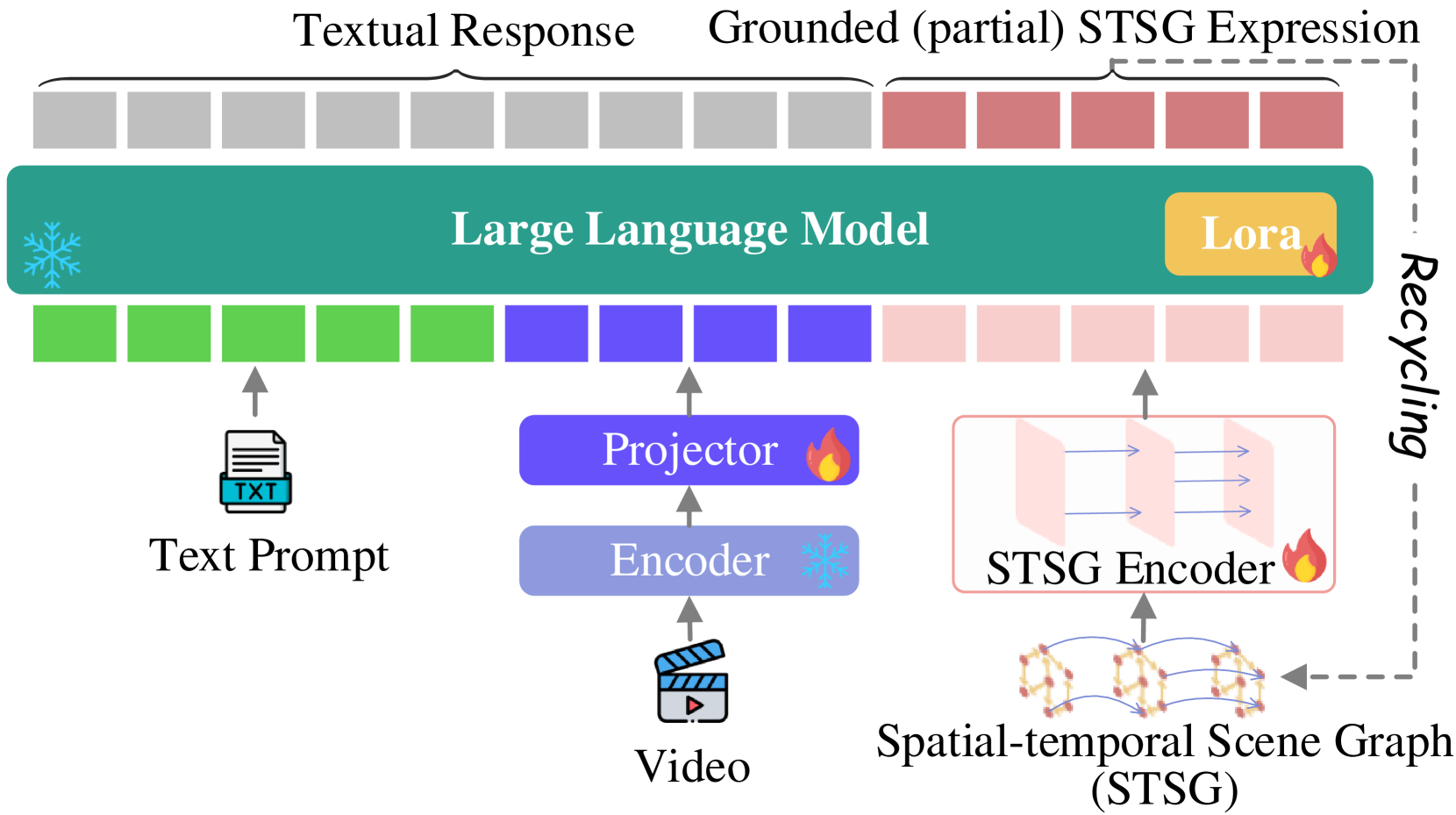
Schematic overview of the MotionEpic architecture.
Breakthrough Assessment
8/10
Proposes a logically sound hierarchy for video reasoning that addresses the grounding-hallucination gap in MLLMs. The integration of explicit scene graph generation within the reasoning chain is a significant methodological advance.
