📝 Paper Summary
Efficient Reasoning
Latent Space Reasoning
CoLaR dynamically compresses sequences of reasoning tokens into probabilistic latent embeddings optimized via reinforcement learning, enabling models to reason silently with adjustable speed and accuracy.
Core Problem
Explicit Chain-of-Thought (CoT) reasoning generates lengthy token sequences that are computationally expensive, while existing latent reasoning methods rely on fixed-length compression and deterministic predictions that limit exploration and accuracy.
Why it matters:
- Extended reasoning chains create substantial server loads and latency in real-world applications, especially under high concurrency
- Current token-skipping methods still operate on sparse representations, missing the efficiency gains of dense latent processing
- Prior latent methods (Coconut, CODI) lack adaptability because they cannot dynamically adjust reasoning speed or explore diverse reasoning paths during training
Concrete Example:
For the step '<< 21 / 7 = 3 >>', explicit CoT generates 5+ tokens sequentially. CoLaR with a compression factor c=4 merges these into a single dense latent vector, effectively 'thinking' the step in one forward pass rather than five, while maintaining the semantic state for the next calculation.
Key Novelty
Compressed Latent Reasoning (CoLaR)
- Introduces a dynamic compression mechanism where 'c' consecutive tokens are merged into a single latent embedding, with 'c' randomly sampled during training to support variable inference speeds
- Employs a probabilistic Latent Head that predicts the mean and variance of the next compressed embedding, enabling the exploration of diverse reasoning paths
- Applies reinforcement learning (GRPO) directly on latent sequences to encourage the model to find correct answers using the shortest possible reasoning chains
Architecture
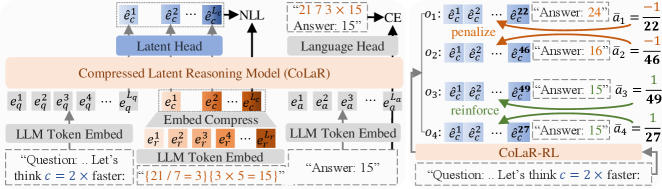
The CoLaR training framework, showing the auxiliary next-compressed-embedding prediction task and the input structure with compressed latents.
Evaluation Highlights
- Achieves 14.1% higher accuracy than latent-based baselines (Coconut, CODI) at comparable compression ratios on mathematical reasoning datasets
- Reduces reasoning chain length by 53.3% with only 4.8% performance degradation compared to explicit Chain-of-Thought
- RL-enhanced CoLaR on the challenging MATH dataset gains up to 5.36% accuracy while reducing reasoning chain length by 82.8% compared to baselines
Breakthrough Assessment
8/10
Strong conceptual advance in latent reasoning by introducing dynamic compression and probabilistic RL exploration, addressing key rigidity issues in prior works like Coconut.