📝 Paper Summary
End-to-End Autonomous Driving
Vision-Language-Action (VLA) Models
Safety-Critical Planning
Alpamayo-R1 improves autonomous driving safety in rare scenarios by integrating a vision-language model with a diffusion-based trajectory planner, using reinforcement learning to align explicit causal reasoning with physical actions.
Core Problem
Current end-to-end driving models are brittle in rare, safety-critical scenarios because they map pixels directly to actions without causal understanding, while existing reasoning models produce free-form text that is often disconnected from the actual driving trajectory.
Why it matters:
- Safety-critical 'long-tail' events (rare, complex scenarios) remain the primary bottleneck for deploying Level 4 autonomous vehicles
- Purely imitation-based models lack interpretability, making it impossible to verify why a vehicle made a specific dangerous decision
- Existing VLAs treat reasoning as an NLP task, ignoring the structural constraints of driving (lane geometry, dynamics), leading to hallucinations
Concrete Example:
In a scenario with a broken-down vehicle blocking a lane with a solid line, a standard model might freeze or erratically swerve. Alpamayo-R1 generates a trace: 'Obstacle blocking lane -> Oncoming lane clear -> Safe to cross solid line' and outputs a trajectory that smoothly circumvents the obstacle.
Key Novelty
Causally-Grounded Reasoning VLA
- Chain of Causation (CoC): A structured data format that forces the model to link observations (e.g., 'pedestrian stepping out') directly to reasoning ('must yield') and actionable decisions, rather than generating loose narratives
- Reasoning-Action Alignment via RL: Uses reinforcement learning not just for the action, but to reward the reasoning process itself, ensuring the generated explanation actually supports and improves the physical trajectory
Architecture
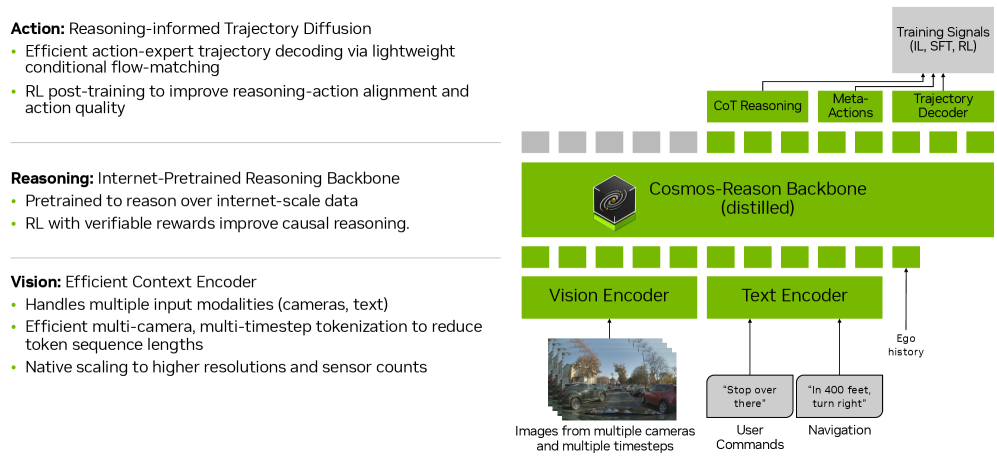
End-to-end architecture of Alpamayo-R1.
Evaluation Highlights
- +12% improvement in planning accuracy on challenging cases compared to a trajectory-only baseline
- 35% reduction in close encounter rate (safety metric) in closed-loop simulation
- RL post-training improves reasoning quality by 45% and reasoning-action consistency by 37%
Breakthrough Assessment
9/10
Significant step forward in 'System 2' thinking for driving. Successfully bridges the gap between high-level language reasoning and low-level control with tangible safety gains and real-time performance.