📝 Paper Summary
Video Understanding
Multimodal Large Language Models (MLLMs)
Reinforcement Learning (RL)
VITAL is an agentic framework that enables MLLMs to reason about long videos by actively sampling frames via a visual toolbox, optimized using a difficulty-aware reinforcement learning algorithm.
Core Problem
Existing MLLMs relying on text-based Chain-of-Thought suffer from insufficient cross-modal interaction and high hallucination rates when reasoning over long videos.
Why it matters:
- Long video understanding is computationally expensive using standard context extension methods
- Text-only reasoning disconnects the model from visual evidence, leading to error accumulation in multi-step tasks
- Current RL post-training methods (like GRPO) suffer from difficulty imbalance when applied to multi-task video domains (e.g., mixing easy QA with hard temporal grounding)
Concrete Example:
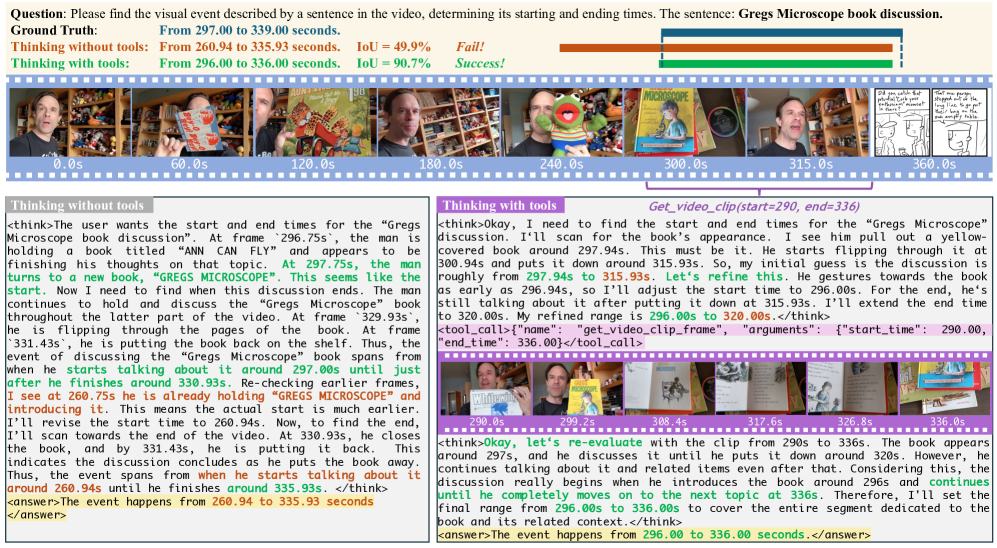
In a temporal grounding task, a text-based CoT model might hallucinate a timestamp based on a single frame or caption, whereas VITAL uses a 'video clipping' tool to actively resample frames at specific intervals, verifying the event's precise start and end times.
Key Novelty
Video Intelligence via Tool-Augmented Learning (VITAL) with Difficulty-aware GRPO
- Introduces a visual toolbox (specifically video clipping) allowing the model to 'think with videos' by iteratively requesting and processing new visual information during the reasoning chain
- Proposes Difficulty-aware Group Relative Policy Optimization (DGRPO) which scales rewards based on task and sample difficulty to prevent easy tasks from dominating the learning process
- Constructs two large-scale datasets (MTVR-CoT-72k and MTVR-RL-110k) specifically filtered for reasoning difficulty to support the tool-augmented training
Architecture
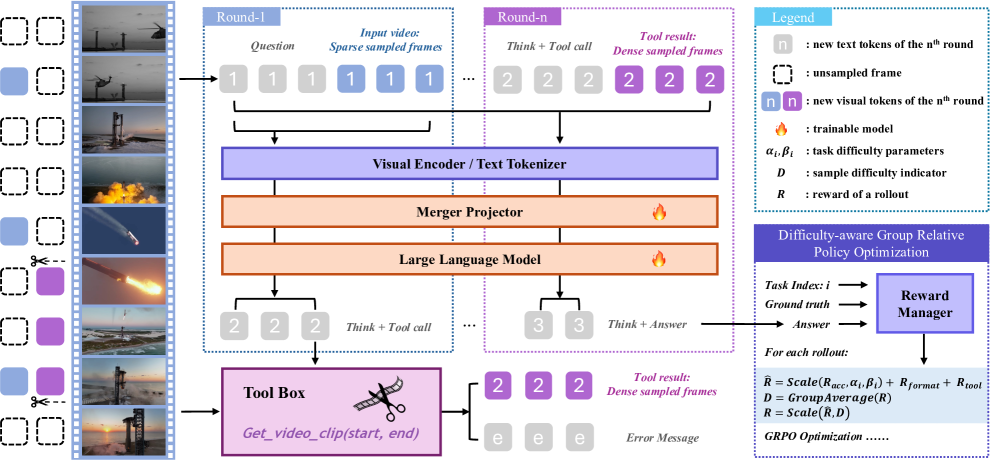
The overall framework of VITAL, illustrating the multi-round tool-augmented reasoning process.
Evaluation Highlights
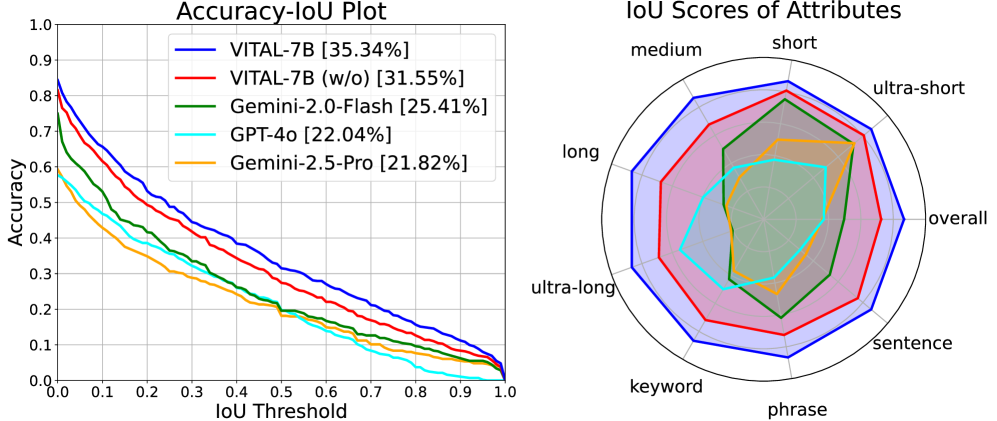
- +11.4% accuracy improvement on LongVideo-Reason (79.3% vs 67.9%) compared to the previous best open-source model
- +7.3% Recall@1 improvement on VidChapters-7M temporal grounding (34.7% vs 27.4%)
- DGRPO training increases average performance on difficult benchmarks from 50.3 to 52.1 compared to standard GRPO
Breakthrough Assessment
8/10
Significant performance jumps on long video benchmarks by successfully integrating tool use with RL. The difficulty-aware optimization addresses a common failure mode in multi-task RL.