📝 Paper Summary
Vision-Language Models (VLMs)
Reinforcement Learning (RL)
Visual Reasoning
ViGoRL improves visual reasoning by training VLMs to explicitly anchor every textual thought to specific image coordinates, enabling active visual exploration and verification via reinforcement learning.
Core Problem
Standard Vision-Language Models (VLMs) process images globally and abstractly, failing to actively inspect specific regions. Naïve reinforcement learning amplifies this behavior, encouraging models to find shortcuts rather than developing genuine visual search strategies.
Why it matters:
- Current models treat vision as static context, leading to poor performance on tasks requiring sequential search (e.g., finding small objects in clutter).
- Without grounding, models hallucinate reasoning steps without verifying them against visual evidence.
- RL typically fails to induce new capabilities like backtracking or zooming unless these behaviors are already present in the model's sampling distribution.
Concrete Example:
When asked to solve a spatial reasoning task, a standard Qwen2.5-VL-3B model generates abstract text without referencing image locations, examining only 1.44 regions on average and never backtracking. In contrast, ViGoRL explicitly outputs coordinates for each thought, allowing it to verify hypotheses and correct errors.
Key Novelty
Visually Grounded Reinforcement Learning (ViGoRL)
- Redefines a reasoning step as a tuple containing both a textual thought and a spatial coordinate (x,y), forcing the model to 'point' to evidence while thinking.
- Uses Monte Carlo Tree Search (MCTS) with a strong teacher model to generate synthetic training data that demonstrates active exploration and backtracking.
- Introduces a multi-turn RL framework where the model can use a 'crop' tool to zoom into predicted coordinates, simulating the human behavior of shifting gaze to gather fine-grained details.
Architecture
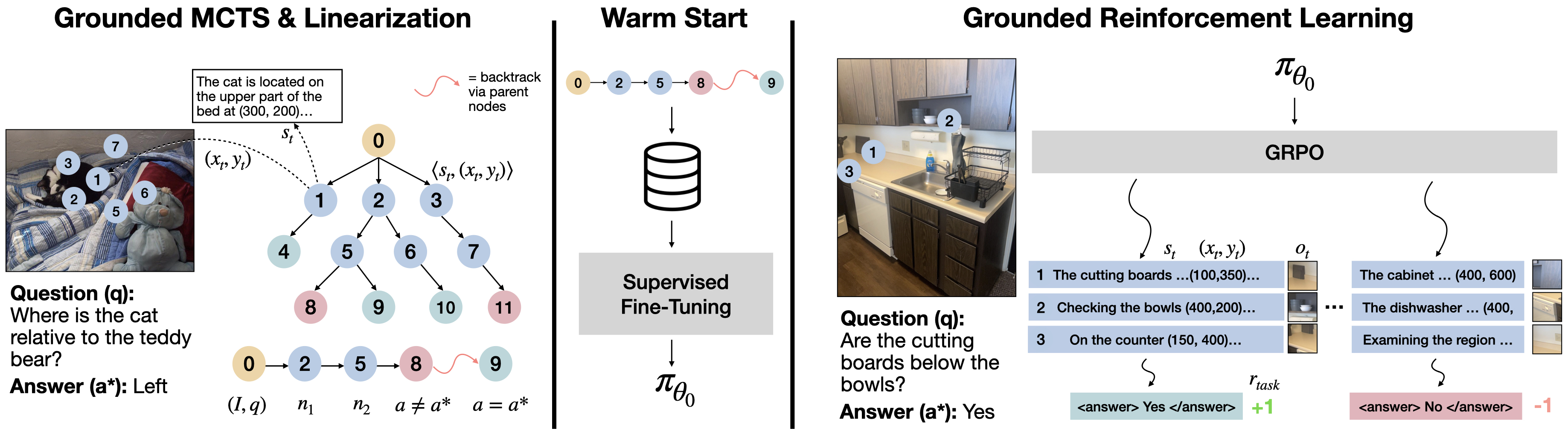
The three-stage training pipeline: (1) MCTS exploration with a teacher to create grounded traces, (2) Supervised Fine-Tuning (Warm-start) on these traces, and (3) Reinforcement Learning (GRPO) to optimize the policy.
Evaluation Highlights
- +12.9% accuracy improvement on the SAT-2 spatial reasoning benchmark compared to vanilla GRPO (Group Relative Policy Optimization).
- Achieves 86.4% accuracy on V*Bench, outperforming both VLM tool-use pipelines and proprietary models.
- Surpasses ICAL on VisualWebArena (web interaction from images) despite using only visual input, while ICAL typically uses HTML/DOM access.
Breakthrough Assessment
9/10
Significantly advances VLM reasoning by solving the 'ungrounded thought' problem. Successfully demonstrates that grounding is a prerequisite for RL to induce complex behaviors like visual verification and backtracking.
