📝 Paper Summary
LLM Quantization
Reasoning Models
A systematic study reveals that while 8-bit quantization is safe for reasoning models, 4-bit quantization causes significant degradation, especially on harder tasks and smaller models, with varying sensitivity across model families.
Core Problem
Reasoning models like DeepSeek-R1 improve performance via long chain-of-thought processes but suffer from high inference overheads. Standard quantization methods used for non-reasoning LLMs may degrade these delicate reasoning chains.
Why it matters:
- Inference costs for reasoning models are prohibitively high due to extended output lengths (often 100x longer than standard LLMs)
- Quantization errors might accumulate over long chain-of-thought sequences, causing the model to deviate from correct logical paths
- Existing quantization research focuses on general LLMs, leaving the specific sensitivity of reasoning-specialized models under-explored
Concrete Example:
A DeepSeek-R1-Distill-Qwen-1.5B model drops over 10% in accuracy on AIME-120 when using 4-bit weight-activation quantization, whereas non-reasoning tasks often tolerate similar compression with less loss.
Key Novelty
First systematic empirical study of quantized reasoning models
- Evaluates impact of Weight, KV Cache, and Activation quantization across varied bit-widths on specialized reasoning models (DeepSeek-R1 distillations, QwQ)
- Identifies that task difficulty is a key predictor of quantization failure (harder math problems suffer 4x more degradation than simple ones)
- Discovers that unlike standard LLMs, quantized reasoning models do not hallucinate longer outputs but simply fail in accuracy
Architecture
Overview of the study's scope: evaluating Quantization Methods (Weight, Activation, KV Cache) on Reasoning Models (Distilled, RL-based) across various Reasoning Benchmarks.
Evaluation Highlights
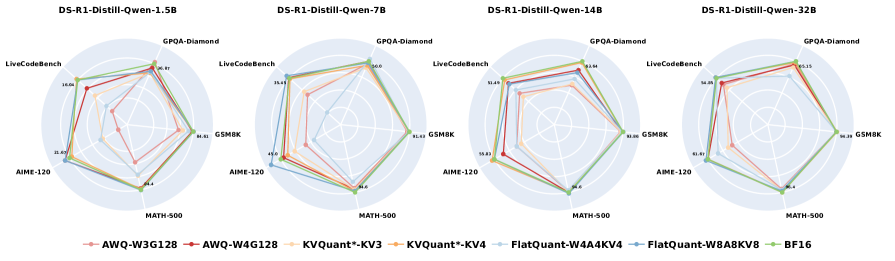
- W8A8KV8 quantization is near-lossless (<1% drop) across all models and tasks, even for 1.5B models.
- Harder tasks like AIME-120 suffer up to 4x greater degradation from quantization than simpler tasks like GSM8K.
- DeepSeek-R1-Distill-Qwen-32B drops only 0.4% accuracy with 4-bit weights but crashes by >3% with 3-bit weights.
Breakthrough Assessment
7/10
Provides critical empirical guidance for deploying efficient reasoning models. While not proposing a new algorithm, the comprehensive benchmarking of existing methods on this new model class is highly valuable for practitioners.