📝 Paper Summary
Neuro-symbolic AI
Visual Question Answering (VQA)
Code Generation for Reasoning
ViperGPT solves visual tasks by prompting a code-generation LLM to write Python programs that orchestrate pre-trained vision models via a defined API, enabling zero-shot reasoning without training.
Core Problem
End-to-end vision models struggle with compositional reasoning and math, while prior modular networks required difficult joint training of program generators and modules, limiting generalization.
Why it matters:
- End-to-end 'black box' models are uninterpretable and cannot reliably perform simple mathematical operations (e.g., division) or logic steps necessary for complex queries
- Training modular systems from scratch is unstable and data-hungry; leveraging existing strong pre-trained models without retraining allows for immediate adaptation to new tasks
Concrete Example:
Query: 'How many muffins can each kid eat for it to be fair?' End-to-end models fail to count and divide accurately. ViperGPT generates Python code that detects muffins (8) and kids (2) using an API, then executes `8 // 2` to return '4'.
Key Novelty
Visual Inference via Python Execution
- Replaces the learned neural program generator with a pre-trained code LLM (Codex) that translates natural language queries into executable Python code
- Uses the standard Python interpreter as the 'reasoning engine' (for logic, math, control flow) and pre-trained vision models as the 'sensory engine' (for perception), connected via a simple class-based API
Architecture
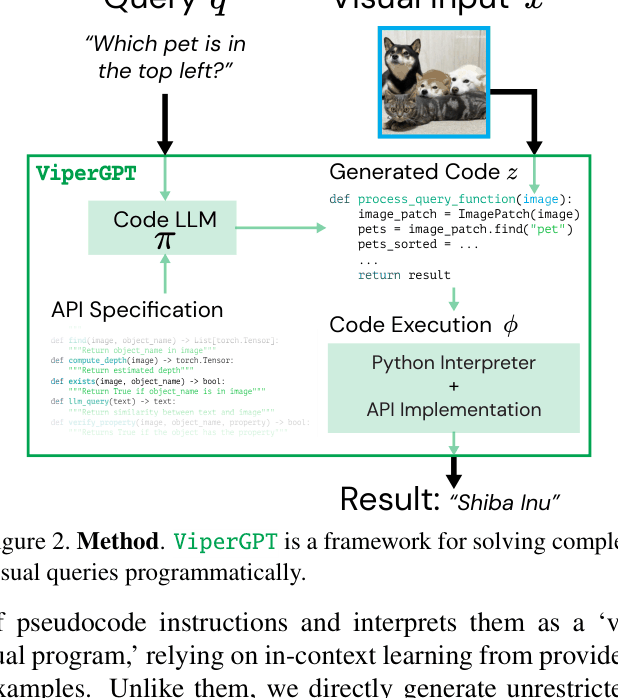
The conceptual framework of ViperGPT, showing the flow from query to code to execution
Evaluation Highlights
- Achieves 72.0% accuracy on RefCOCO visual grounding (zero-shot), outperforming the GLIP baseline by +17.0%
- Surpasses 80-billion parameter Flamingo model on OK-VQA (External Knowledge) with 51.9% accuracy despite being zero-shot
- Attains state-of-the-art results on NExT-QA video reasoning (60.0%), outperforming supervised baselines on hard temporal/causal splits
Breakthrough Assessment
9/10
Demonstrates a highly effective, training-free paradigm shift where LLMs act as controllers for vision tools via code. The performance gaps over supervised or larger end-to-end models are significant.