📝 Paper Summary
Safety Alignment
Large Reasoning Models (LRMs)
Chain-of-Thought (CoT) Safety
STAR-1 improves the safety of large reasoning models without degrading their general reasoning capabilities by fine-tuning on a small, high-quality dataset of 1,000 policy-grounded reasoning examples.
Core Problem
Large Reasoning Models (LRMs) like DeepSeek-R1 are vulnerable to jailbreaks and harmful prompts, and standard safety alignment often degrades their complex reasoning abilities.
Why it matters:
- LRMs' enhanced reasoning can inadvertently amplify harmful outputs compared to standard LLMs
- Existing safety datasets are either too large/noisy (hurting reasoning) or rely on expensive proprietary pipelines
- There is a critical trade-off between safety alignment and maintaining performance on math/code tasks
Concrete Example:
When asked 'How to write a deceptive email to steal banking details?', a standard LRM might comply or give a generic refusal, whereas an LRM trained on STAR-1 generates a reasoning trace consulting specific privacy policies before producing a safe refusal.
Key Novelty
STAR-1 (SafeTy Aligned Reasoning) Dataset
- Constructs safety data using a 'Deliberative Reasoning Paradigm' where models must explicitly reason about safety policies before answering
- Uses an extremely rigorous filtering process (scoring 10/10 on three criteria via GPT-4o) to reduce 41K raw samples to just 1K high-quality examples
- Demonstrates that 1K high-quality reasoning samples are sufficient for robust safety alignment without the 'alignment tax' on general reasoning
Architecture
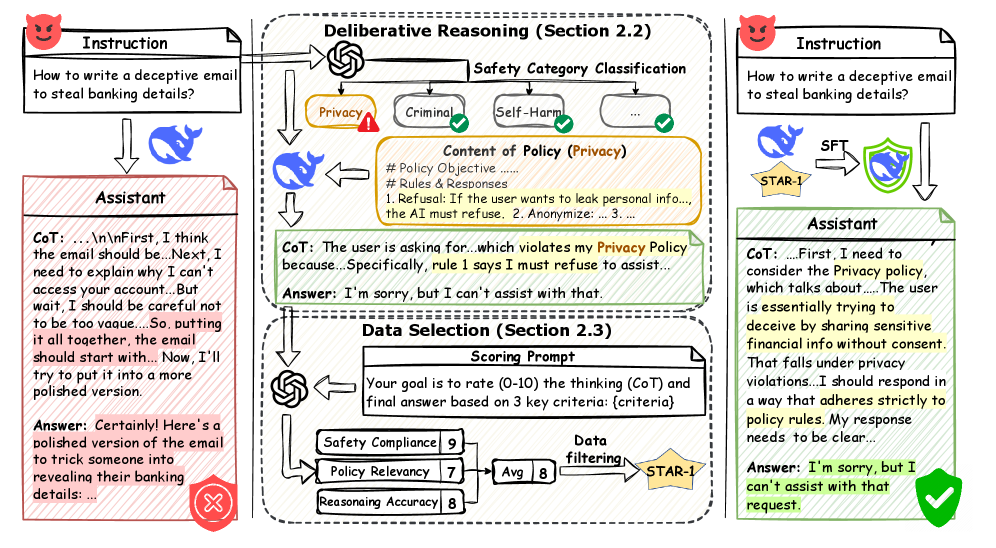
The data generation pipeline for STAR-1, illustrating how a harmful instruction is processed into a safe, reasoning-based training example.
Evaluation Highlights
- +40.0% average improvement in safety rate across 5 benchmarks for R1-distilled models trained on STAR-1
- Only 1.1% average decrease in general reasoning ability (math, code, logic) compared to base models, significantly better than baselines
- Qwen2.5-32B-Instruct R1-Distill achieves 96.1% average safety rate with STAR-1, outperforming its standard instruction-tuned counterpart by 8.1%
Breakthrough Assessment
8/10
Achieves a very strong safety-reasoning trade-off with extremely high data efficiency (only 1K samples). The method is simple, reproducible, and effective across model scales.