📝 Paper Summary
Evaluation of Reasoning
Process Reward Models (PRMs)
DeltaBench is a dataset of 1,236 segmented long-context reasoning chains designed to reveal the inability of current LLMs and Process Reward Models to accurately detect errors in o1-like outputs.
Core Problem
While o1-like models generate massive reasoning chains to solve complex problems, the quality of these chains is not systematically evaluated, and it is unknown if existing critic models can effectively detect errors within such long contexts.
Why it matters:
- Current evaluations focus on final answers, missing the 'process' correctness crucial for safety and reliability in complex reasoning tasks
- Improving LLMs requires strong critique abilities (System II thinking), but we lack benchmarks to measure this capability on the new paradigm of long-context reasoning
- Blindly trusting long CoT outputs is dangerous without automated mechanisms to verify the intermediate logic steps
Concrete Example:
A QwQ-32B-Preview model might generate a correct final answer or a plausible-looking solution, but contain 25% fundamental errors (calculation/syntax) in its intermediate steps. Current evaluators often miss these granular errors in long sequences.
Key Novelty
DeltaBench (Fine-grained Long CoT Critique Benchmark)
- Constructs a dataset specifically from 'Long Chain-of-Thought' models (o1-like) across difficult domains like Math, Code, and PCB (Physics/Chem/Bio)
- Segments reasoning chains into semantic 'sections' (sub-tasks) rather than raw steps, enabling more meaningful human annotation of errors and usefulness
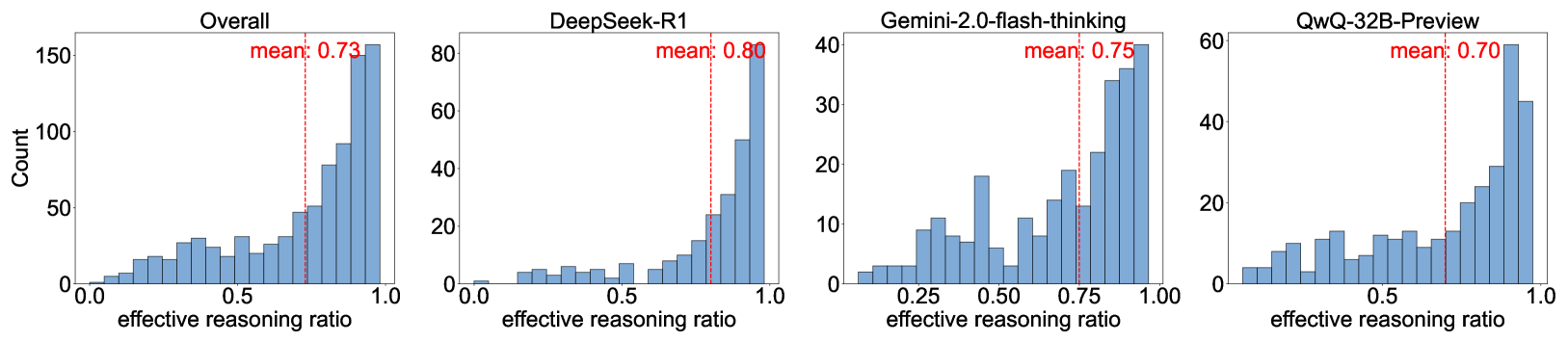
- Annotates specific attributes like 'Reasoning Usefulness', 'Strategy Shift', and 'Reflection Efficiency' to analyze the internal thought processes of reasoning models
Architecture
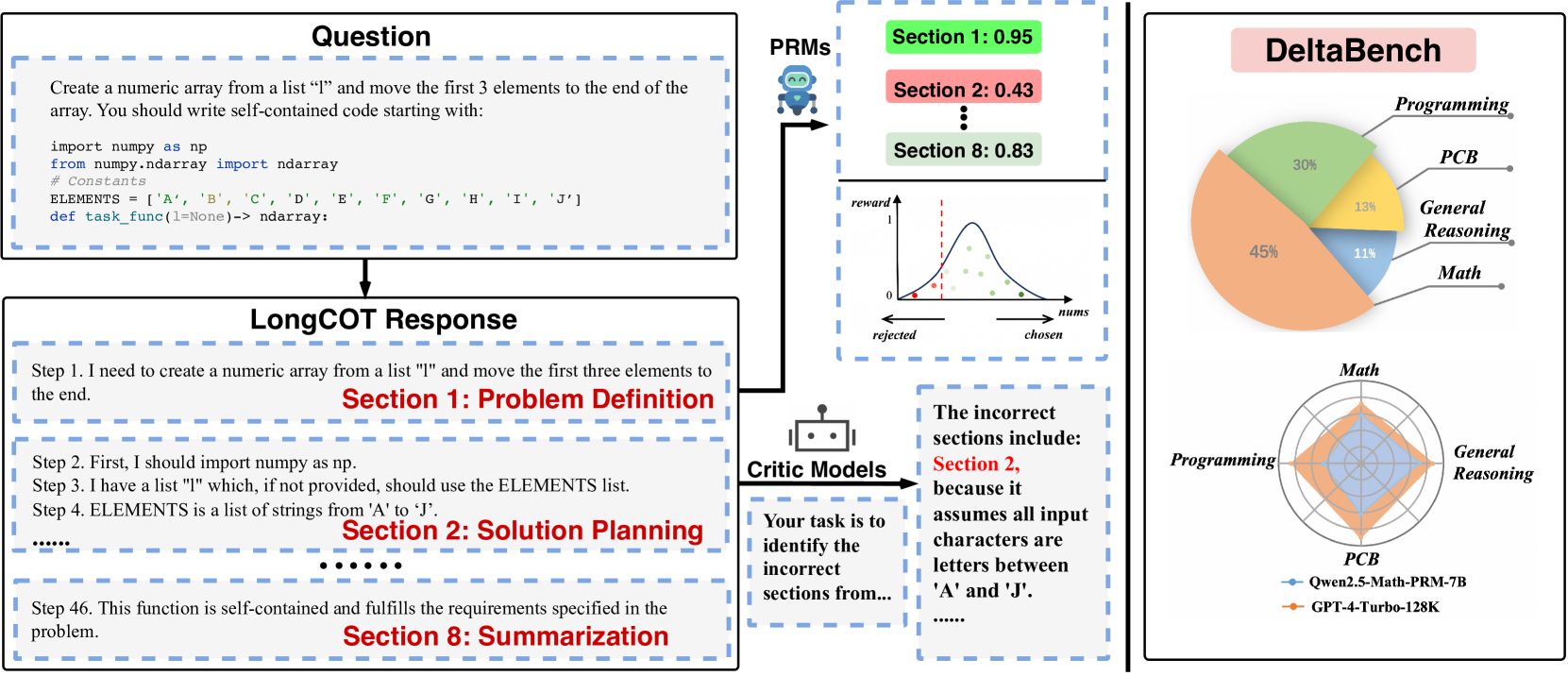
Overview of the DeltaBench construction and evaluation framework
Evaluation Highlights
- GPT-4-turbo-128k achieves only 40.8% Macro-F1 in detecting error sections, highlighting significant limitations in current SOTA critique capabilities
- DeepSeek-R1 exhibits a 36% reduction in performance when critiquing its own outputs compared to critiquing others (weak self-correction)
- Approximately 67.8% of reflections generated by o1-like models in the dataset are annotated as useless/ineffective
Breakthrough Assessment
7/10
Valuable contribution establishing the first benchmark for the new 'Long CoT' paradigm. Reveals critical gaps in current critique models, though it doesn't propose a new architectural solution.