📝 Paper Summary
LLM Reasoning
Inference-time scaling
Speculative Decoding
A training-free inference framework where a large reasoning model selectively intervenes to guide a smaller model's thinking process when specific structural cues like double newlines and reflection keywords appear.
Core Problem
Small language models often struggle with complex reasoning, producing lengthy, verbose incorrect answers characterized by excessive self-reflection and backtracking, while large models are accurate but too costly for full inference.
Why it matters:
- Small models are essential for real-world deployment due to lower compute/memory costs but lack robustness on hard tasks.
- Existing solutions like fine-tuning are costly and data-intensive; inference-time scaling often yields inconsistent improvements on complex tasks.
- Large models have high latency and cost, making them impractical to use for generating every token.
Concrete Example:
When a small model gets stuck, it might output a loop of 'wait, let me check... alternatively... hmm...' followed by wrong reasoning. A large model would spot this 'wait' signal, intervene, and provide a concise, correct next step.
Key Novelty
Speculative Thinking (Reasoning-Level Collaboration)
- Operates at the reasoning/thought level rather than the token level (unlike standard speculative decoding).
- Uses structural cues (paragraph breaks '\n\n' followed by keywords like 'wait' or 'verify') to detect when a small model is struggling or reflecting.
- Delegates only the difficult or reflective segments to a larger 'mentor' model, which generates a high-quality thought step before returning control to the small model.
Architecture
The Speculative Thinking workflow. It shows the small model generating text until a delimiter ('\n\n'), followed by a decision block that checks for keywords (Affirmation, Reflection, Verification). If triggered, the large model takes over for n tokens.
Evaluation Highlights
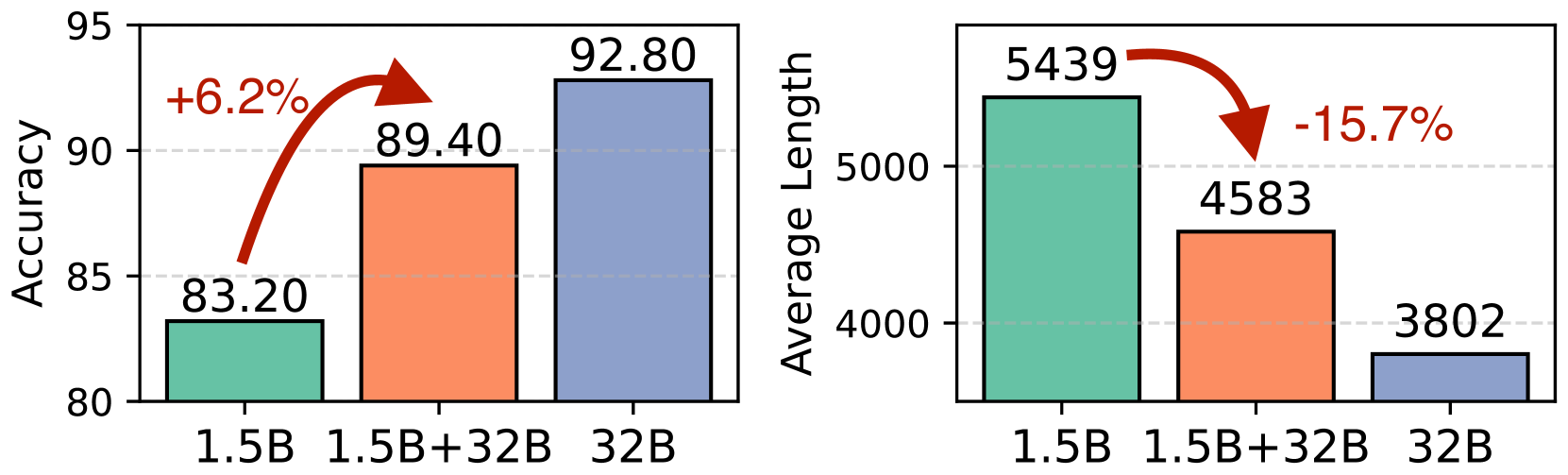
- +6.2% accuracy improvement (83.2% → 89.4%) on MATH500 for a 1.5B model assisted by a 32B model.
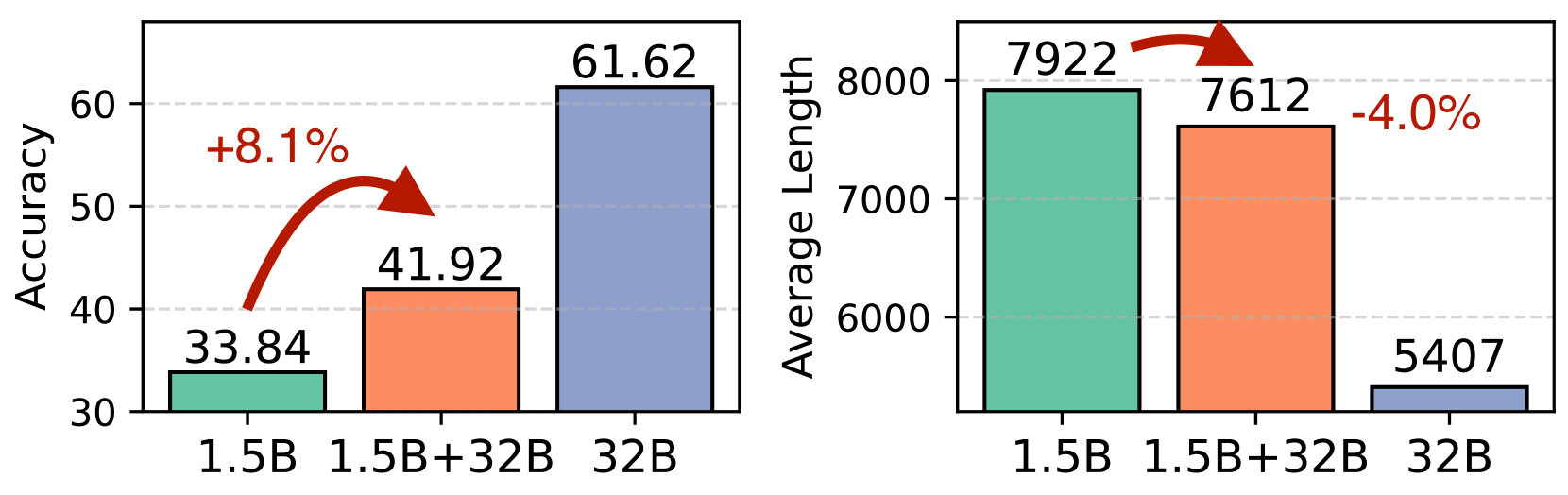
- +8.1% accuracy improvement on GPQA-Diamond for the same 1.5B/32B pair.
- Reduces average output length by 15.7% (5439 → 4583 tokens) on MATH500, indicating more efficient reasoning paths.
Breakthrough Assessment
7/10
Significant practical value for deploying small models. It effectively trades off a small amount of large-model compute for large gains in small-model reliability without retraining.