📊 Experiments & Results
Evaluation Setup
Comparative analysis of Reasoning vs. Non-Reasoning models on Well-defined vs. MiP variants of math problems
Benchmarks:
- MiP-GSM8K (Grade school math with removed numerical conditions) [New]
- MiP-SVAMP (Elementary math with swapped body/question pairs) [New]
- MiP-MATH (Challenging math problems with removed premises) [New]
- MiP-Formula (Synthetic formulas with unassigned variables) [New]
Metrics:
- Response Length (token count)
- Abstain Rate (percentage)
- Cosine Similarity of Reasoning Steps
- Statistical methodology: Not explicitly reported in the paper
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| Comparison of response lengths shows explosive growth for reasoning models on MiP questions compared to well-defined ones, while non-reasoning models remain stable. | ||||
| GSM8K | Response Length (DeepSeek-R1) | 1000 | 3000 | +2000 |
| GSM8K | Response Length (Non-reasoning models) | 200 | 200 | 0 |
| MiP-GSM8K | Step-level Cosine Similarity | 0.45 | 0.50 | +0.05 |
| MiP-GSM8K | Step-level Similarity Variance | 0.0079 | 0.00082 | -0.00708 |
Experiment Figures
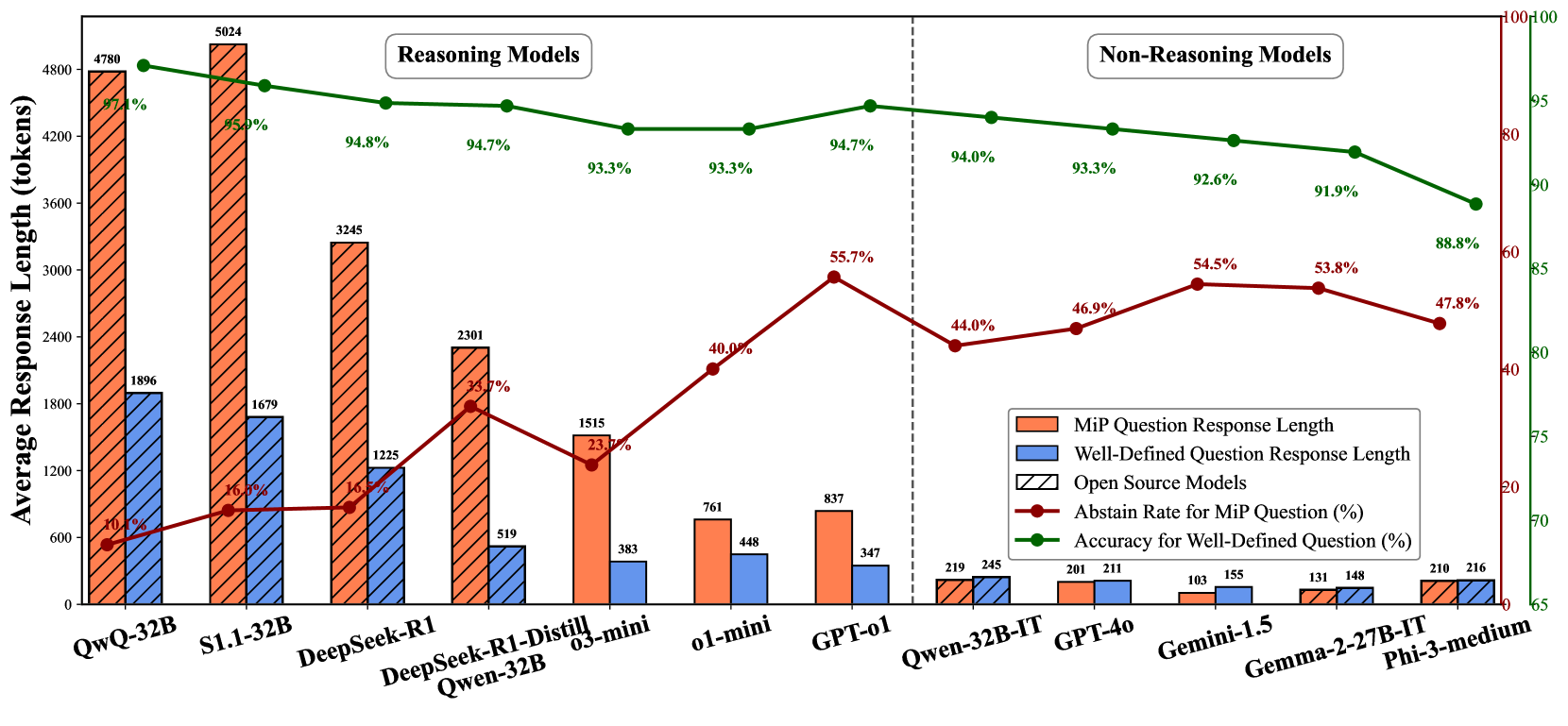
Comparison of Response Length, Accuracy, and Abstain Rate across various LLMs for well-defined vs. MiP questions.
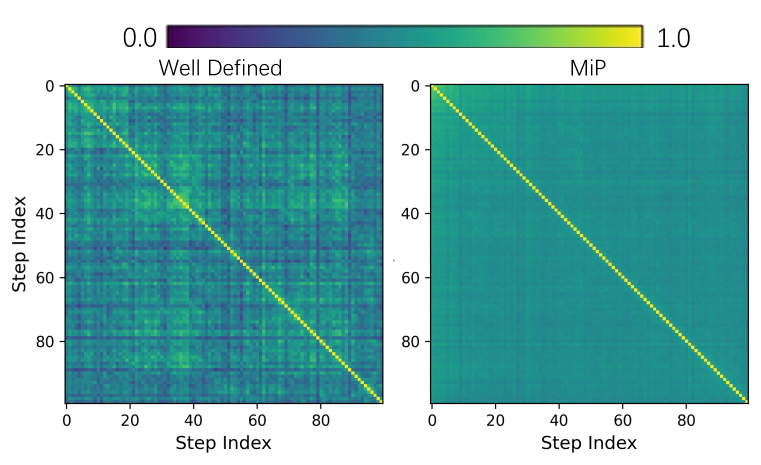
Heatmap of step-level cosine similarity within model responses on MiP-GSM8K.
Main Takeaways
- Reasoning models (like DeepSeek-R1, QwQ) exhibit 'MiP-Overthinking', generating 2-4x more tokens for unsolvable questions than solvable ones, contradicting test-time scaling expectations.
- The increased token count in reasoning models consists largely of 'self-doubt loops' (repeating checks, 'wait', 'alternatively') rather than productive critical thinking.
- Non-reasoning models are surprisingly more robust to Missing Premise (MiP) questions, quickly abstaining with short responses.
- Harder datasets (MiP-MATH) exacerbate the issue, causing even longer redundant reasoning chains and lower abstain rates across models.