📝 Paper Summary
Multimodal Large Language Models (MLLMs)
Preference Optimization
Reasoning
The paper introduces a scalable pipeline for generating multimodal reasoning preference data and a Mixed Preference Optimization method that combines relative preference, absolute quality, and generation losses to improve MLLM Chain-of-Thought performance.
Core Problem
Open-source MLLMs suffer from distribution shifts during Chain-of-Thought (CoT) reasoning, often performing worse with CoT than with direct answers due to the disconnect between teacher-forced training and autoregressive inference.
Why it matters:
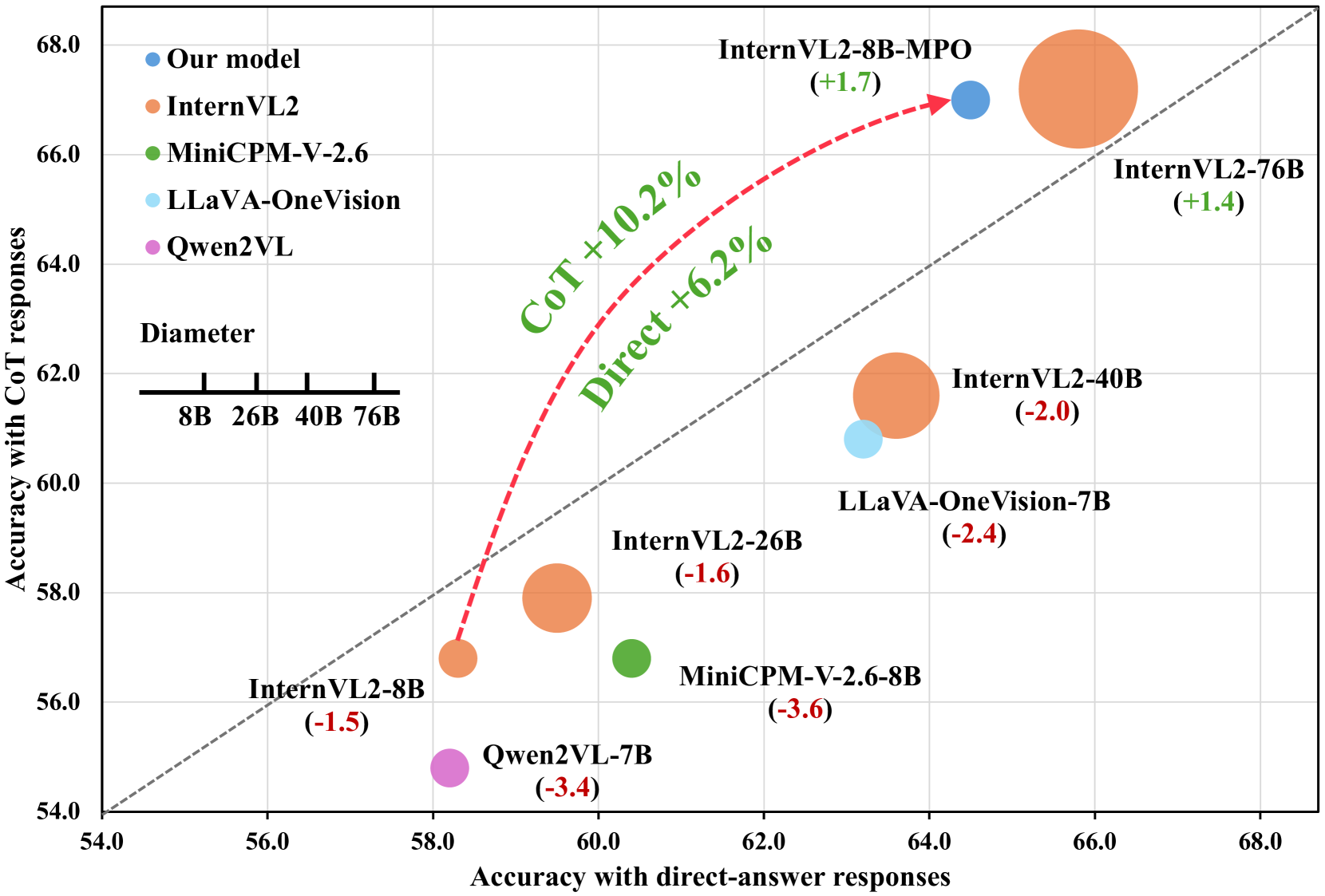
- CoT is crucial for complex reasoning, but current SFT methods degrade performance on MLLMs (e.g., InternVL2-8B drops from 58.3 to 56.8 on MathVista with CoT)
- Existing multimodal preference datasets focus on hallucination reduction in natural images, lacking scientific/reasoning data
- Annotating reasoning processes for multimodal data is prohibitively expensive and time-consuming
Concrete Example:
On MathVista, InternVL2-8B scores 58.3 with direct answers but drops to 56.8 when forced to use Chain-of-Thought. The model fails to maintain coherent long-context reasoning because the SFT loss does not account for the distribution shift between training (teacher forcing) and inference (autoregressive generation).
Key Novelty
Mixed Preference Optimization (MPO) and Scalable Preference Data Pipeline (MMPR)
- Creates a large-scale preference dataset (MMPR) using 'Dropout Next Token Prediction' to automatically generate negative reasoning samples by truncating and completing responses without image access
- Proposes MPO, a training objective combining DPO (relative preference), BCO (absolute quality), and SFT (generation capability) to align models with high-quality reasoning paths without a reward model
Architecture

The automated preference data construction pipeline showing two paths: Correctness-based for ground truth data and Dropout NTP for open-ended data.
Evaluation Highlights
- +8.7 accuracy improvement on MathVista for InternVL2-8B-MPO (67.0) compared to the base InternVL2-8B model (58.3)
- InternVL2-8B-MPO achieves performance comparable to the 10x larger InternVL2-76B on MathVista
- Data construction pipeline reduces token cost to 57.5% of the RLAIF-V divide-and-conquer method while maintaining effectiveness
Breakthrough Assessment
8/10
Significant performance gains on hard reasoning benchmarks (MathVista) and a clever, scalable data construction method (Dropout NTP) that addresses the bottleneck of multimodal preference data scarcity.