📝 Paper Summary
Mathematical Reasoning
Reinforcement Learning from Feedback
WizardMath improves mathematical reasoning in LLMs by fine-tuning on diverse, evolved instructions and optimizing via reinforcement learning using both instruction-quality and step-by-step process supervision.
Core Problem
Open-source LLMs struggle with complex multi-step mathematical reasoning compared to proprietary models like GPT-4, and standard supervised fine-tuning often suffers from hallucinations or false positives where incorrect reasoning leads to correct answers.
Why it matters:
- Mathematical reasoning requires rigorous logic that standard pre-training on internet data often fails to instill
- Existing open-source models lag significantly behind closed-source models (GPT-4, Claude 2) in quantitative reasoning tasks
- Outcome-based supervision (checking only the final answer) is insufficient for ensuring correct logical steps in complex problem solving
Concrete Example:
In a multi-step math problem, a model might make two calculation errors that cancel each other out, arriving at the correct final answer (False Positive). Standard outcome supervision rewards this, reinforcing bad logic, whereas WizardMath's process supervision detects and penalizes the incorrect intermediate steps.
Key Novelty
Reinforcement Learning from Evol-Instruct Feedback (RLEIF)
- Extends Evol-Instruct to mathematics by adding 'Downward Evolution' (simplifying problems) alongside 'Upward Evolution' (complicating problems) to create a diverse difficulty curriculum
- Introduces an Instruction Reward Model (IRM) to judge the quality/definition of evolved questions and a Process-Supervised Reward Model (PRM) to verify reasoning steps
- Integrates these into a PPO (Proximal Policy Optimization) loop where the reward is a product of instruction quality and solution correctness
Architecture
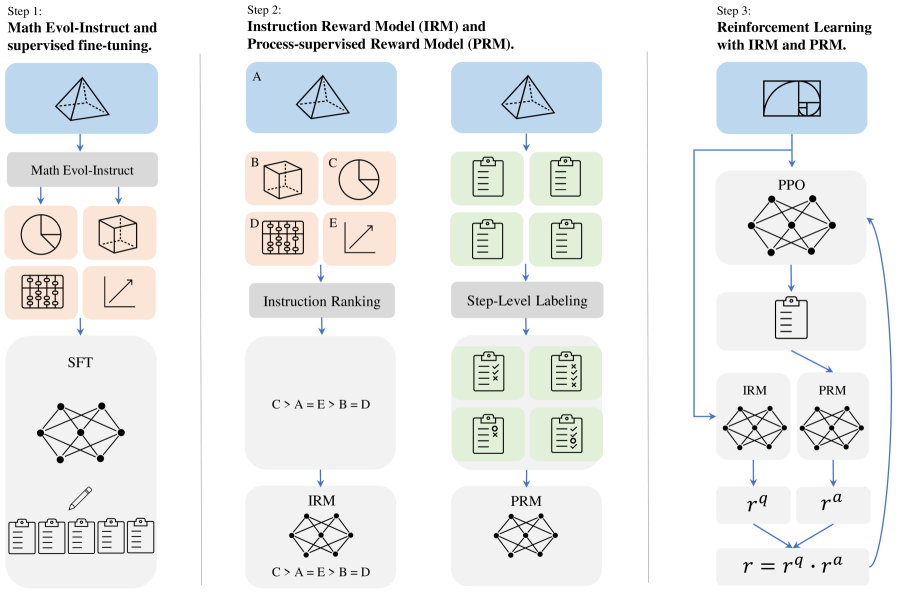
Overview of the RLEIF method. It shows the pipeline from Math Evol-Instruct to Reward Model training (IRM & PRM) and finally PPO training.
Evaluation Highlights
- WizardMath-70B outperforms GPT-4 (early version), Claude-2, and Gemini Pro on GSM8K (81.6 pass@1) and MATH (22.7 pass@1) benchmarks
- WizardMath-Mistral-7B achieves +12.8% improvement on GSM8k and +26.8% on MATH compared to MetaMath-Mistral-7B
- Combining PRM and IRM yields a 6-8% improvement over SFT baselines, validating the RLEIF approach
Breakthrough Assessment
8/10
Significant jump in open-source math reasoning performance, surpassing much larger proprietary models. The combination of evolutionary data generation with process supervision (RLEIF) is a strong methodological contribution.