📊 Experiments & Results
Evaluation Setup
Zero-shot or Few-shot prompting on standard reasoning benchmarks
Benchmarks:
- GSM8K (Grade school math reasoning)
- CommonSenseQA (Commonsense reasoning (multiple choice))
- HotpotQA (Multi-hop Question Answering)
Metrics:
- Accuracy
- Exact Match
- Concept Coverage (for constrained generation)
- Statistical methodology: Not explicitly reported in the paper
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| Experiments on Intrinsic Self-Correction (no oracle) show performance degradation across multiple models and benchmarks. | ||||
| GSM8K | Accuracy | 77.4 | 75.9 | -1.5 |
| GSM8K | Accuracy | 92.0 | 91.5 | -0.5 |
| CommonSenseQA | Accuracy | 66.8 | 55.4 | -11.4 |
| CommonSenseQA | Accuracy | 63.0 | 51.0 | -12.0 |
| Comparison of Multi-Agent Debate against Self-Consistency (controlling for compute cost). | ||||
| GSM8K | Accuracy | 84.7 | 84.7 | 0.0 |
| GSM8K | Accuracy | 86.8 | 84.7 | -2.1 |
| Re-evaluation of Constrained Generation (Madaan et al.) with improved initial prompts. | ||||
| Constrained Generation | Concept Coverage | 61.3 | 66.7 | +5.4 |
Experiment Figures
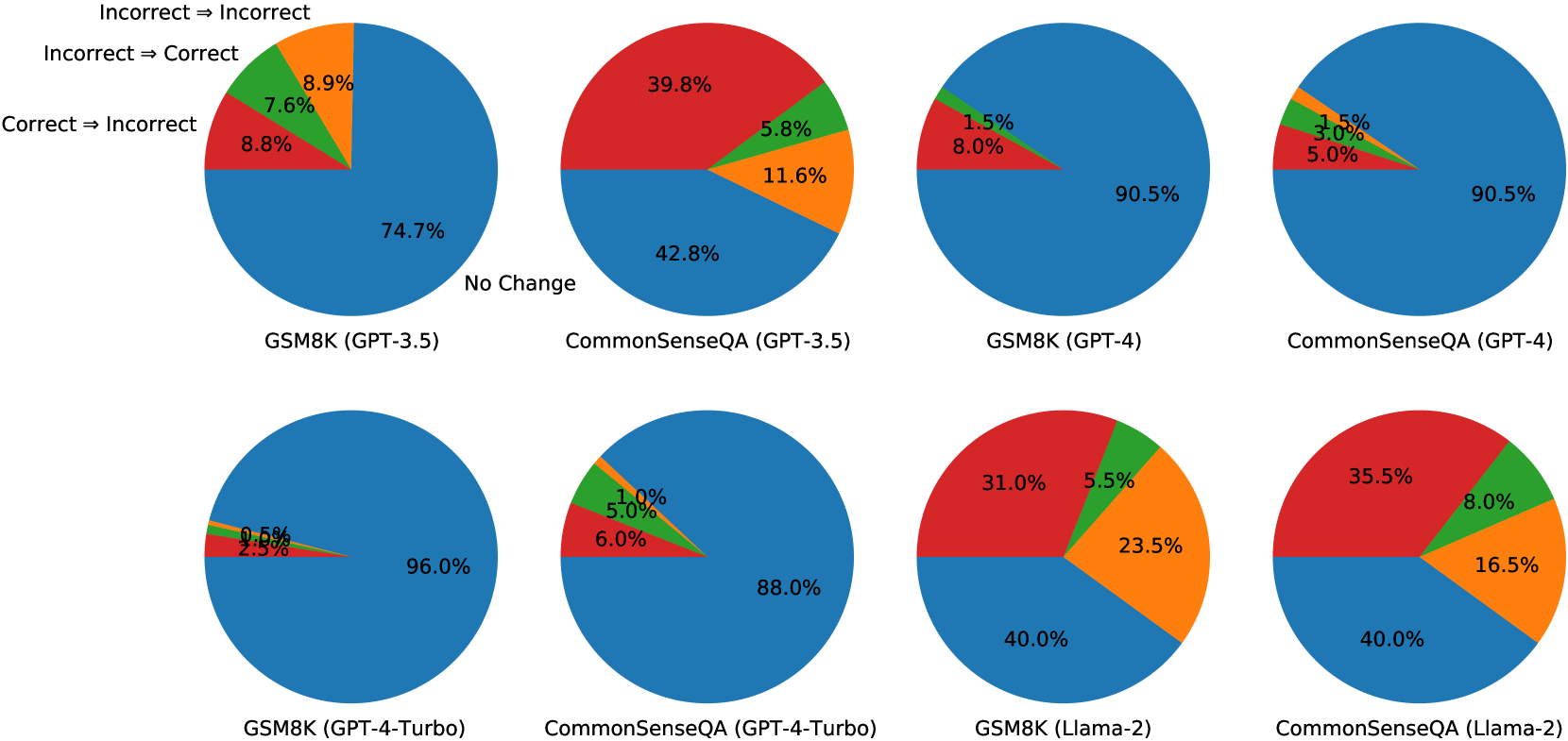
Bar charts showing the transition of answer correctness after self-correction (Correct→Correct, Correct→Incorrect, Incorrect→Correct, Incorrect→Incorrect).
Main Takeaways
- Oracle labels create an illusion of self-correction capability; without them, models struggle to identify their own errors.
- Models are more likely to change a correct answer to an incorrect one than to fix an incorrect answer (e.g., in GSM8K).
- Multi-agent debate essentially functions as a consistency check (majority vote) rather than a reasoning refinement process.
- Claims of self-correction success in prior work often stem from sub-optimal initial prompts; fixing the prompt is more effective than adding a correction loop.