📝 Paper Summary
LLM Reasoning
Reinforcement Learning from Human Feedback (RLHF)
Preference Learning
Enhances LLM reasoning capabilities by using Monte Carlo Tree Search to iteratively generate granular step-level preference data, which is then used to update the policy via Direct Preference Optimization.
Core Problem
Standard preference learning relies on sparse instance-level supervision (only final answer correctness) and static offline datasets, failing to provide granular feedback for complex multi-step reasoning.
Why it matters:
- Instance-level rewards lose important information about intermediate reasoning steps, limiting model improvement.
- Static offline RLHF does not allow the model to adapt continuously or correct its own specific errors.
- Existing MCTS methods often require training a separate, complex value function (critic), which is difficult to maintain.
Concrete Example:
In a multi-step math problem, a model might make a small error in step 2 but get the final answer wrong. Standard methods penalize the whole chain. This approach uses MCTS to identify that step 2 specifically led to a low-value node compared to a better alternative, creating a specific training signal.
Key Novelty
Iterative MCTS-DPO (MCTS-Enhanced Iterative Preference Learning)
- Uses Monte Carlo Tree Search (MCTS) as a dynamic data generator that explores reasoning paths and labels them with 'preference' based on Q-values (future expected rewards).
- Extracts step-level preference pairs (a good step vs. a bad step at the same decision point) from the MCTS tree rather than just final-outcome pairs.
- Updates the LLM policy using Direct Preference Optimization (DPO) on this self-generated data in an iterative loop, removing the need for a separate frozen reward model.
Architecture
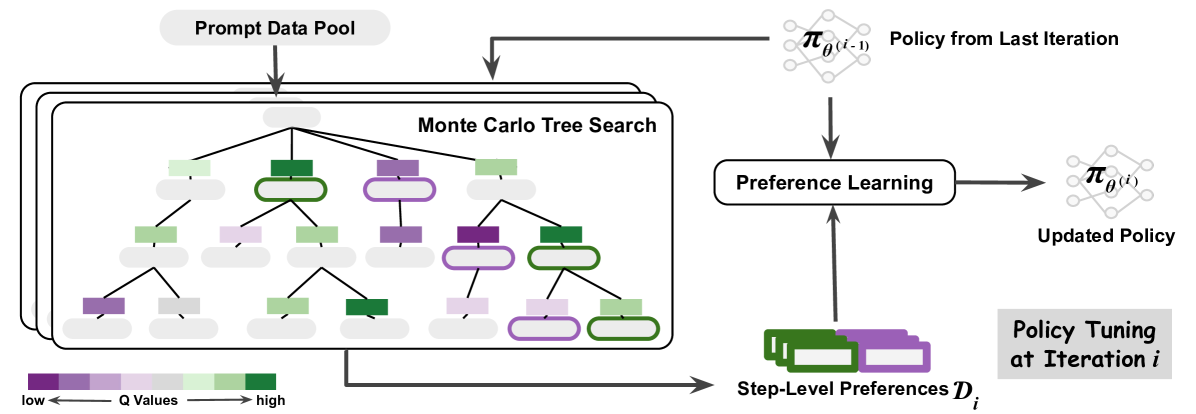
Overview of the MCTS-Enhanced Iterative Preference Learning framework.
Evaluation Highlights
- +5.9% accuracy improvement on GSM8K (81.8%) compared to the Mistral-7B SFT baseline.
- +5.8% accuracy improvement on MATH (34.7%) compared to the Mistral-7B SFT baseline.
- +15.8% accuracy improvement on ARC-C (76.4%) compared to the Mistral-7B SFT baseline.
Breakthrough Assessment
8/10
Strong combination of AlphaZero-style iteration with modern DPO, addressing the key bottleneck of sparse rewards in reasoning tasks. Significant empirical gains on hard benchmarks (MATH, GSM8K).