📝 Paper Summary
Mathematical Reasoning
Fine-tuning Large Language Models
Reinforcement Learning for Reasoning
REFT fine-tunes language models for math reasoning by using PPO to learn from multiple automatically sampled reasoning paths rather than just single ground-truth annotations.
Core Problem
Supervised Fine-Tuning (SFT) relies on a single annotated Chain-of-Thought (CoT) path per question, limiting the model's ability to explore diverse valid reasoning strategies and generalize to new problems.
Why it matters:
- Math problems often have multiple valid reasoning paths, but training data usually provides only one, restricting the model's learning potential.
- SFT models often struggle with generalization; exploring alternative paths via reinforcement learning can provide richer supervision signals.
- Reliance on fixed CoT annotations can lead to overfitting on specific phrasing rather than learning robust problem-solving logic.
Concrete Example:
For a question like 'Weng earns $12/hour...', SFT trains on one specific explanation. If the model generates a valid but different path (e.g., converting minutes to hours differently), SFT doesn't reward it, whereas ReFT samples multiple paths and rewards any that reach the correct numeric answer.
Key Novelty
Reinforced Fine-Tuning (ReFT) for Math
- Warm-up the model with standard SFT, then switch to PPO (Reinforcement Learning) using the same training questions but without the ground-truth reasoning paths.
- Derive rewards automatically by checking if the final answer matches the ground truth, allowing the model to explore and learn from any valid reasoning path it generates.
Architecture
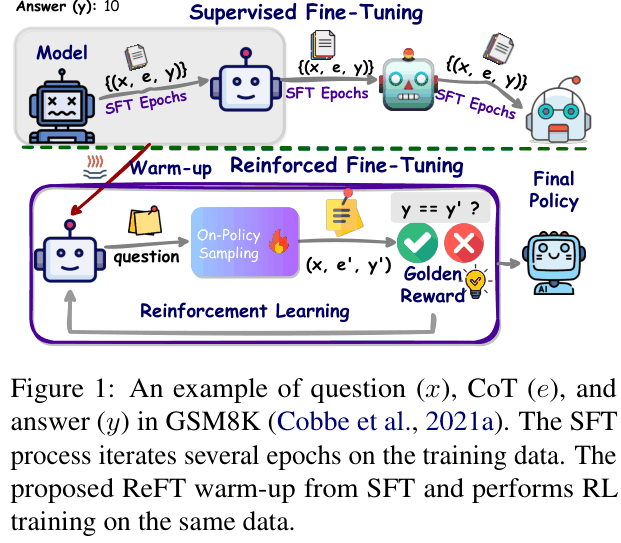
Conceptual comparison between SFT and ReFT processes. SFT trains on fixed (question, CoT, answer) triples. ReFT warms up with SFT, then uses RL (PPO) to sample multiple CoTs (e'), compare their answers (y') to the gold answer (y) to generate rewards, and update the policy.
Evaluation Highlights
- ReFT outperforms SFT by +9.71% accuracy on GSM8K using CodeLLAMA-7B with natural language CoT.
- Achieves 81.2% accuracy on GSM8K using CodeLLAMA-7B with Program-CoT + Reranking, surpassing larger models like MAmmoTH-Coder-70B (76.7%).
- Consistent improvements across GSM8K, SVAMP, and MathQA datasets using both Galactica and CodeLLAMA foundation models.
Breakthrough Assessment
8/10
Simple yet highly effective method that significantly boosts reasoning performance using existing data, without requiring external reward models or extra datasets.