📝 Paper Summary
Prompt Engineering
Reasoning Evaluation
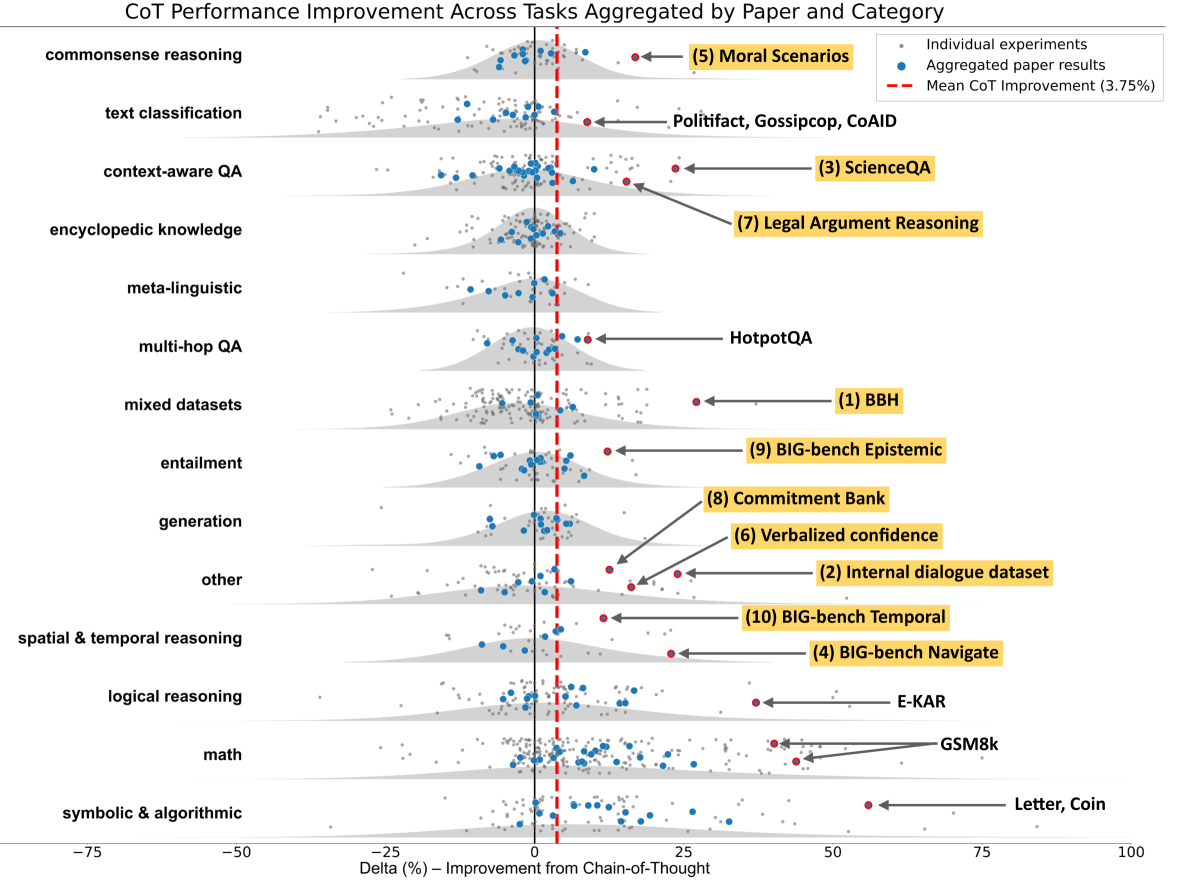
A comprehensive meta-analysis and empirical study demonstrate that Chain-of-Thought prompting provides significant gains primarily on math and symbolic tasks, yielding negligible benefits over direct answering for commonsense or soft reasoning.
Core Problem
Chain-of-Thought (CoT) is widely applied as a default prompting strategy for all reasoning tasks, increasing inference costs without proven benefits outside of mathematical domains.
Why it matters:
- Current LLM deployments (e.g., ChatGPT) often default to CoT, potentially wasting computation on tasks where direct answering is equally effective
- Research benchmarks are heavily skewed toward math (GSM8K, MATH), creating a false perception that CoT is universally beneficial for all 'reasoning'
- Blindly applying CoT to non-symbolic tasks (like commonsense QA) can sometimes hurt performance or introduce unnecessary latency
Concrete Example:
On the MMLU benchmark, CoT provides almost no benefit for generic questions, but for questions containing an equals sign ('=')—indicating symbolic operations—accuracy improves significantly. Directly answering non-math questions yields nearly identical accuracy to CoT.
Key Novelty
Large-Scale CoT Utility Delimitation
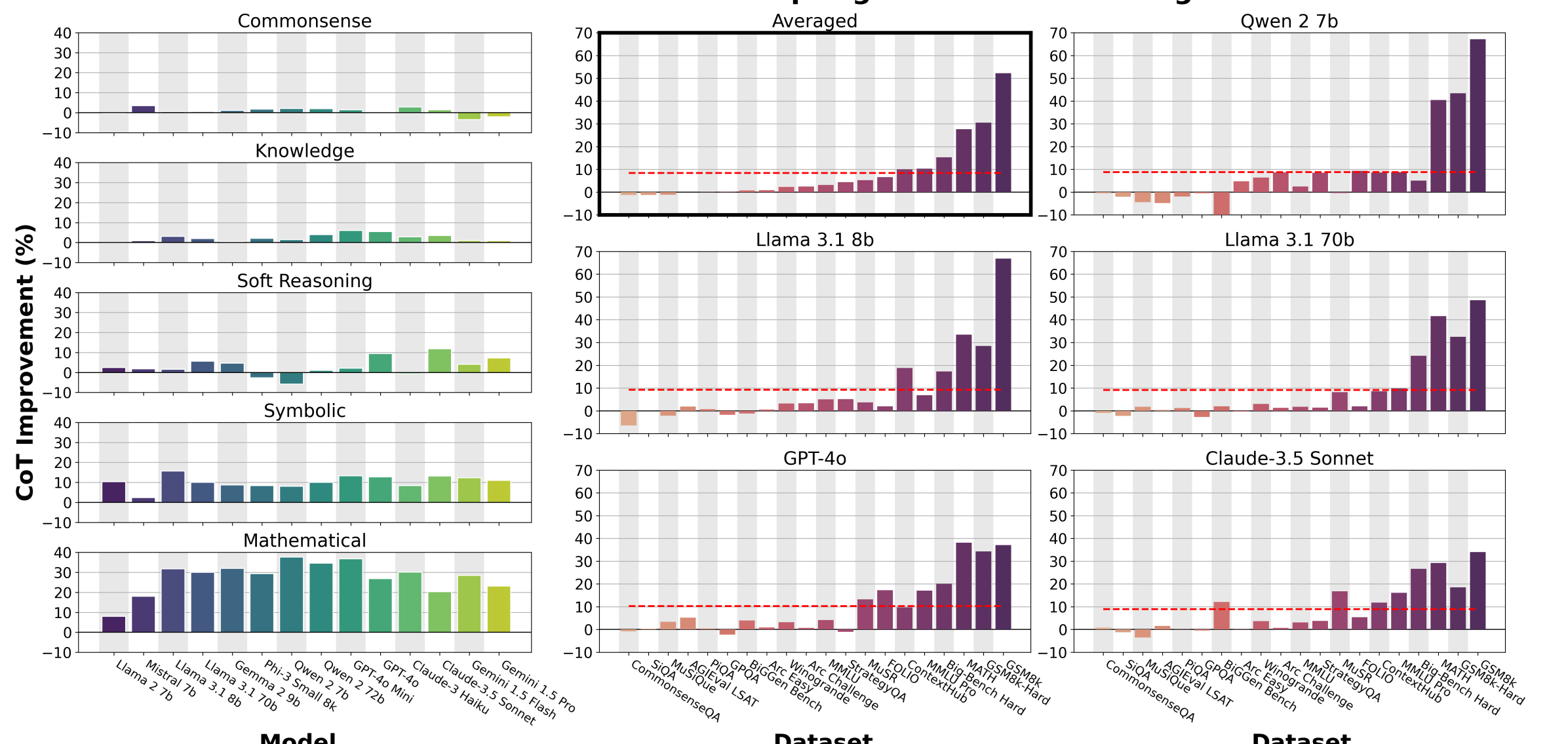
- Conducts a meta-analysis of over 100 papers and new experiments across 20 datasets to rigorously classify where CoT helps versus where it is redundant
- Identifies 'Symbolic Execution' as the primary mechanism for CoT gains, showing that benefits correlate strongly with the presence of formal systems (logic, math) rather than general reasoning
- Demonstrates that for symbolic tasks, tool-augmented LLMs (offloading to solvers) outperform CoT, suggesting CoT is a suboptimal middle ground
Architecture
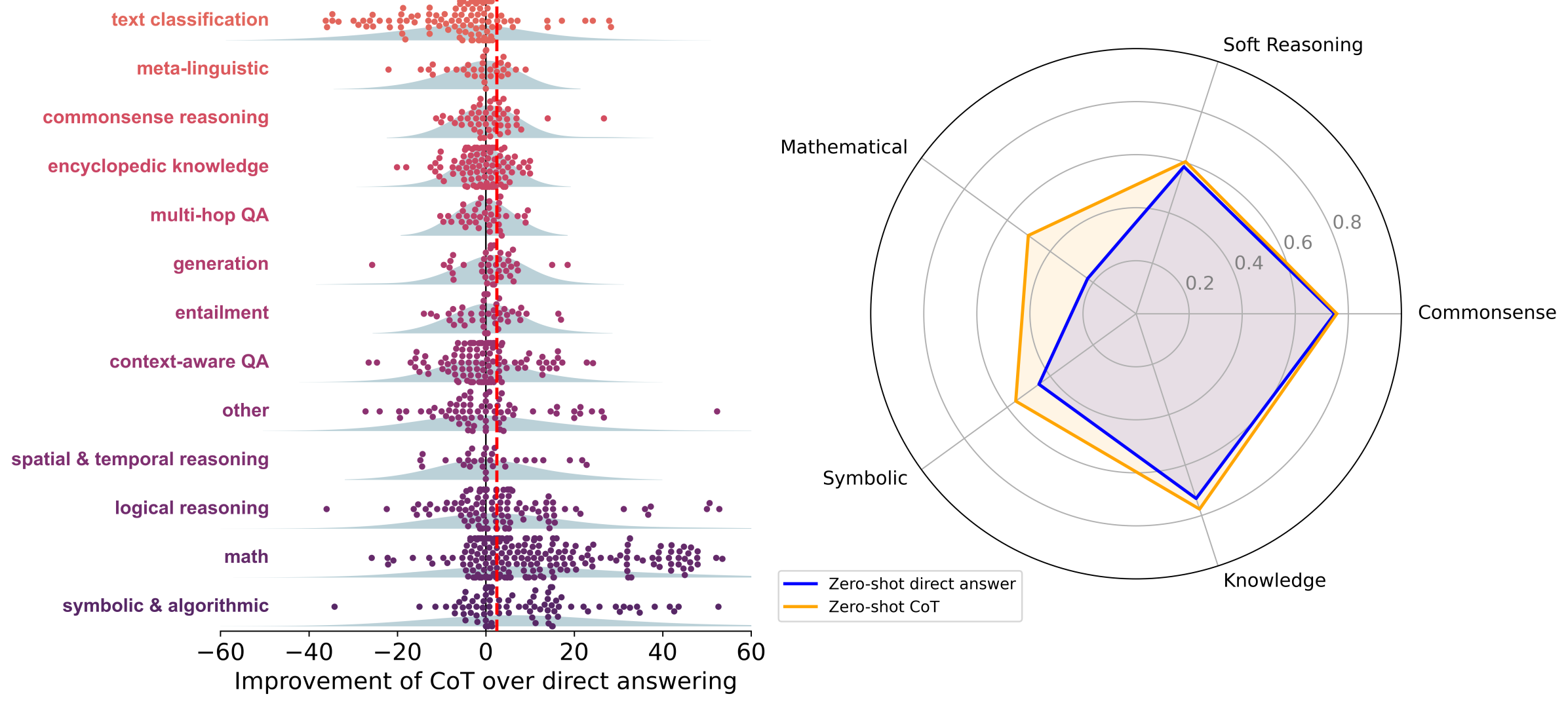
Comparison of CoT utility across different domains (Symbolic vs. Soft Reasoning)
Evaluation Highlights
- Meta-analysis of literature shows huge average gains for CoT on Symbolic (+14.2 points) and Math (+12.3 points) tasks compared to direct answering
- In contrast, 'Other' task categories in the literature show negligible improvement with CoT (average 56.8) vs Direct Answering (average 56.1)
- 95% of the total performance gain from CoT on the MMLU benchmark is attributed specifically to questions containing an equals sign ('=')
Breakthrough Assessment
8/10
Provides a crucial corrective to the field's assumption that CoT is a universal reasoning enhancer. The distinction between symbolic execution and soft reasoning is empirically validated and impactful for efficient deployment.