📝 Paper Summary
Mathematical Reasoning
Reward Modeling
Process Supervision
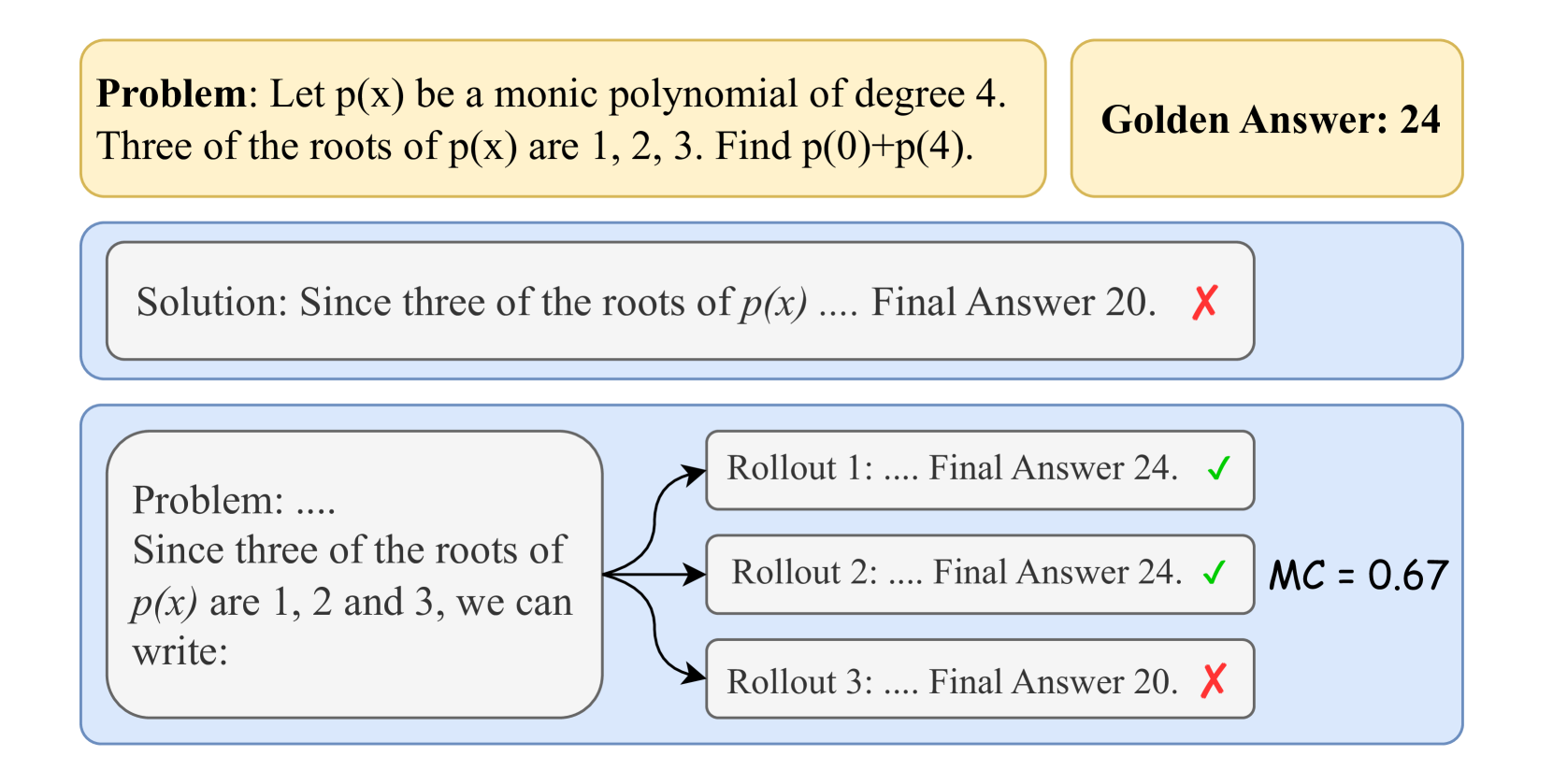
OmegaPRM automates process supervision for math reasoning by using a divide-and-conquer Monte Carlo Tree Search to efficiently locate errors and generate over 1.5 million high-quality training labels without human intervention.
Core Problem
Training Process Reward Models (PRMs) requires granular labels for every reasoning step, but collecting these labels relies on expensive human annotation or inefficient brute-force Monte Carlo estimation.
Why it matters:
- Outcome Reward Models (ORMs) provide sparse feedback, failing to identify where exactly a multi-step reasoning chain goes wrong
- Current automated methods like brute-force rollouts are computationally expensive (linear complexity with respect to solution length)
- Scalable, high-quality process data is the primary bottleneck for improving LLM reasoning capabilities beyond simple prompting
Concrete Example:
In a long math proof, if an LLM makes a mistake at step 4 but the final answer is wrong, an ORM only knows the result is wrong. Finding the exact error requires checking every step. Brute-force methods roll out from step 1, 2, 3... to the end, which is very costly for long chains.
Key Novelty
OmegaPRM: Divide-and-Conquer MCTS for Data Collection
- Uses binary search to locate the first error in a solution chain with logarithmic complexity instead of linear scanning
- Maintains a state-action tree where nodes store Monte Carlo correctness estimates, allowing efficient reuse of rollouts across different branches
- Selects 'convincing wrong' rollouts (high confidence but wrong answer) for annotation to create harder, more valuable training examples
Architecture
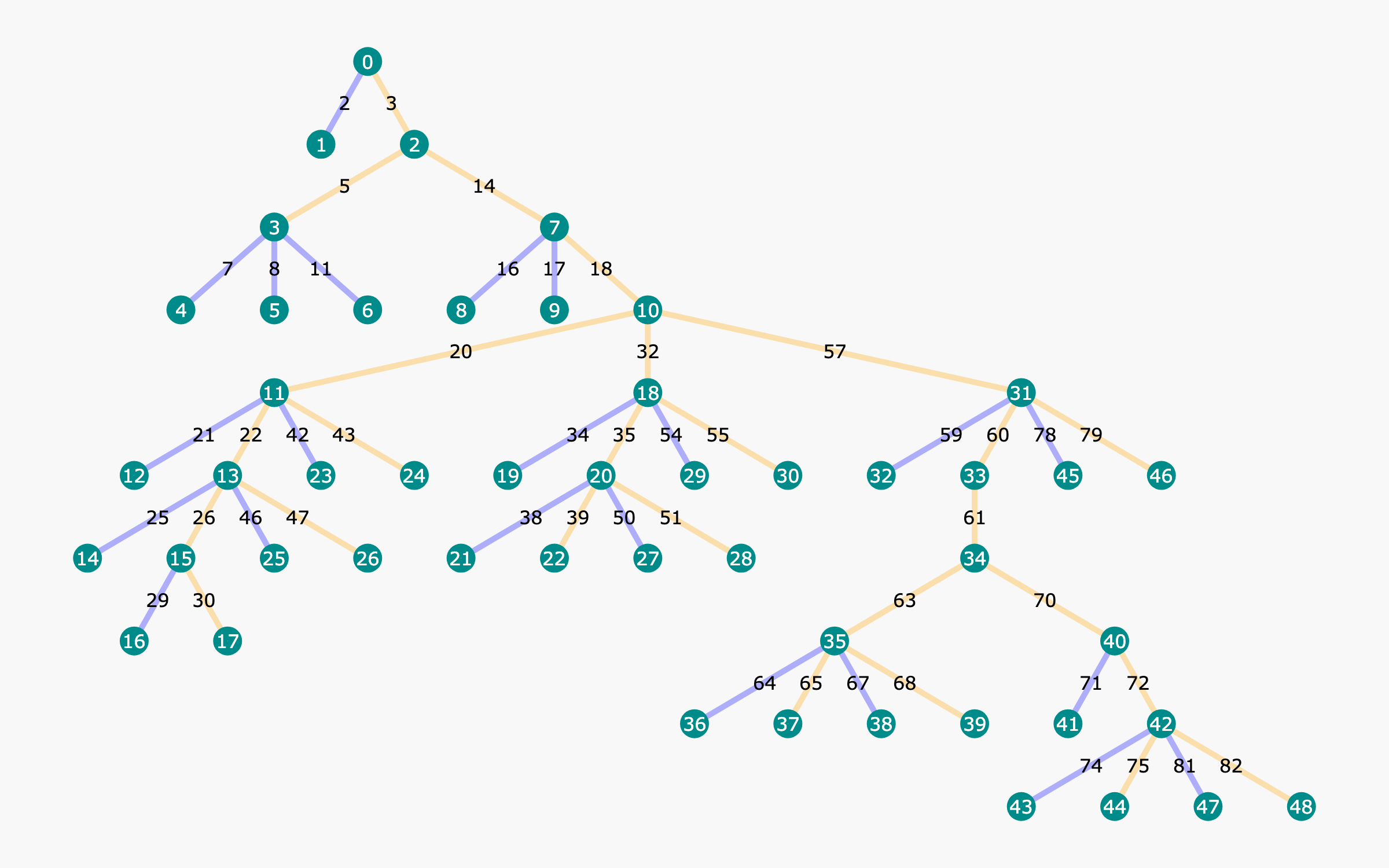
Overview of the OmegaPRM algorithm showing the MCTS process. It illustrates how a question is expanded into a tree of partial solutions, how rollouts are performed, and how binary search is used to locate errors.
Evaluation Highlights
- Gemini Pro success rate improved from 51% to 69.4% on MATH500 and 86.4% to 93.6% on GSM8K using the collected data
- Gemma2 27B success rate boosted from 42.3% to 58.2% on MATH500 and 74.0% to 92.2% on GSM8K
- Collected over 1.5 million automated process supervision annotations without any human intervention
Breakthrough Assessment
8/10
Significant efficiency gain in data collection (O(log N) vs O(N)) allowing massive scaling of process supervision data. The resulting performance gains on major benchmarks are substantial.