📝 Paper Summary
Vision-Language-Action Models (VLAs)
Robot Manipulation
Chain-of-Thought Reasoning
Embodied Chain-of-Thought (ECoT) trains robot policies to predict semantic plans and grounded visual features like bounding boxes before actions, significantly improving generalization and enabling natural language correction.
Core Problem
Standard Vision-Language-Action (VLA) models map observations directly to actions, lacking the ability to reason iteratively through complex tasks or ground high-level plans in physical observation.
Why it matters:
- Reactive policies struggle with broad generalization to novel scenes or unfamiliar objects where 'muscle memory' is insufficient
- Standard Chain-of-Thought (CoT) from LLMs is purely semantic and fails to ground reasoning in sensory observations (e.g., object locations) required for manipulation
- Existing VLAs like OpenVLA perform well on in-distribution tasks but fail to leverage the reasoning capabilities of their LLM backbones for control
Concrete Example:
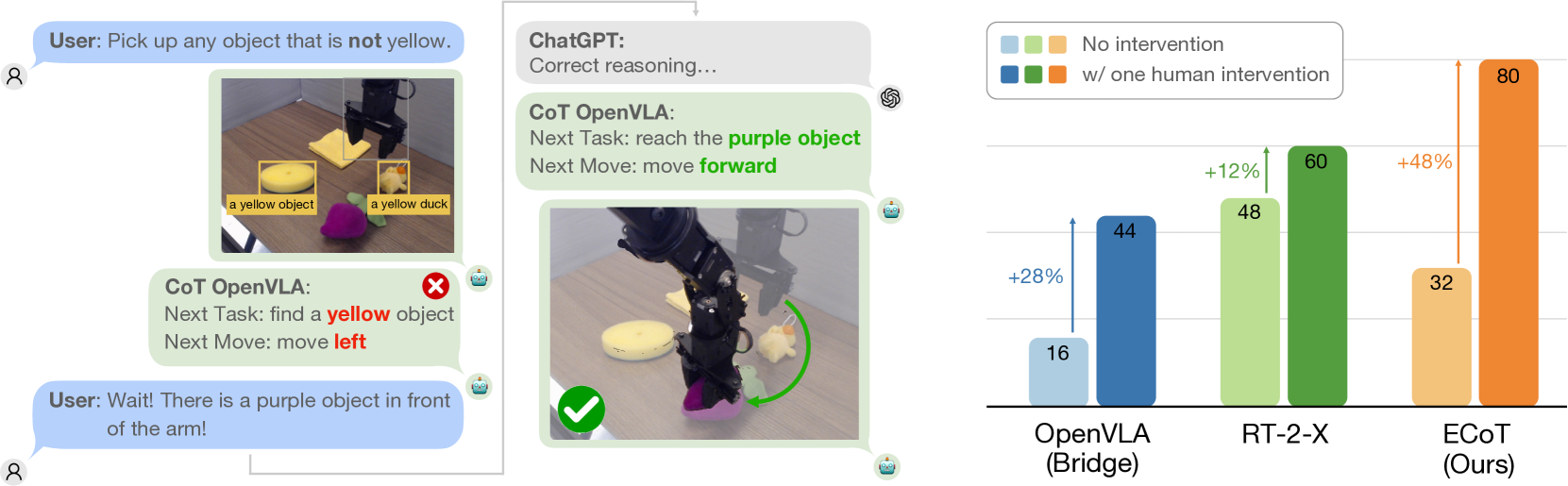
When asked to 'pick up the screwdriver,' a standard policy might grab a hammer if it looks similar. An ECoT policy first reasons 'Identify objects -> Hammer found, Screwdriver found', calculates bounding boxes, realizes the target location, and corrects its trajectory.
Key Novelty
Embodied Chain-of-Thought (ECoT)
- Trains the VLA to autoregressively predict a sequence of reasoning steps—including high-level plans, sub-tasks, movement primitives, and bounding boxes—before predicting the final action
- Interleaves semantic reasoning (what to do) with embodied grounding (where things are), forcing the model to 'look carefully' before acting
- Uses a scalable synthetic data pipeline involving multiple foundation models (VLM, Object Detectors, LLMs) to label existing robot datasets with these reasoning chains
Architecture
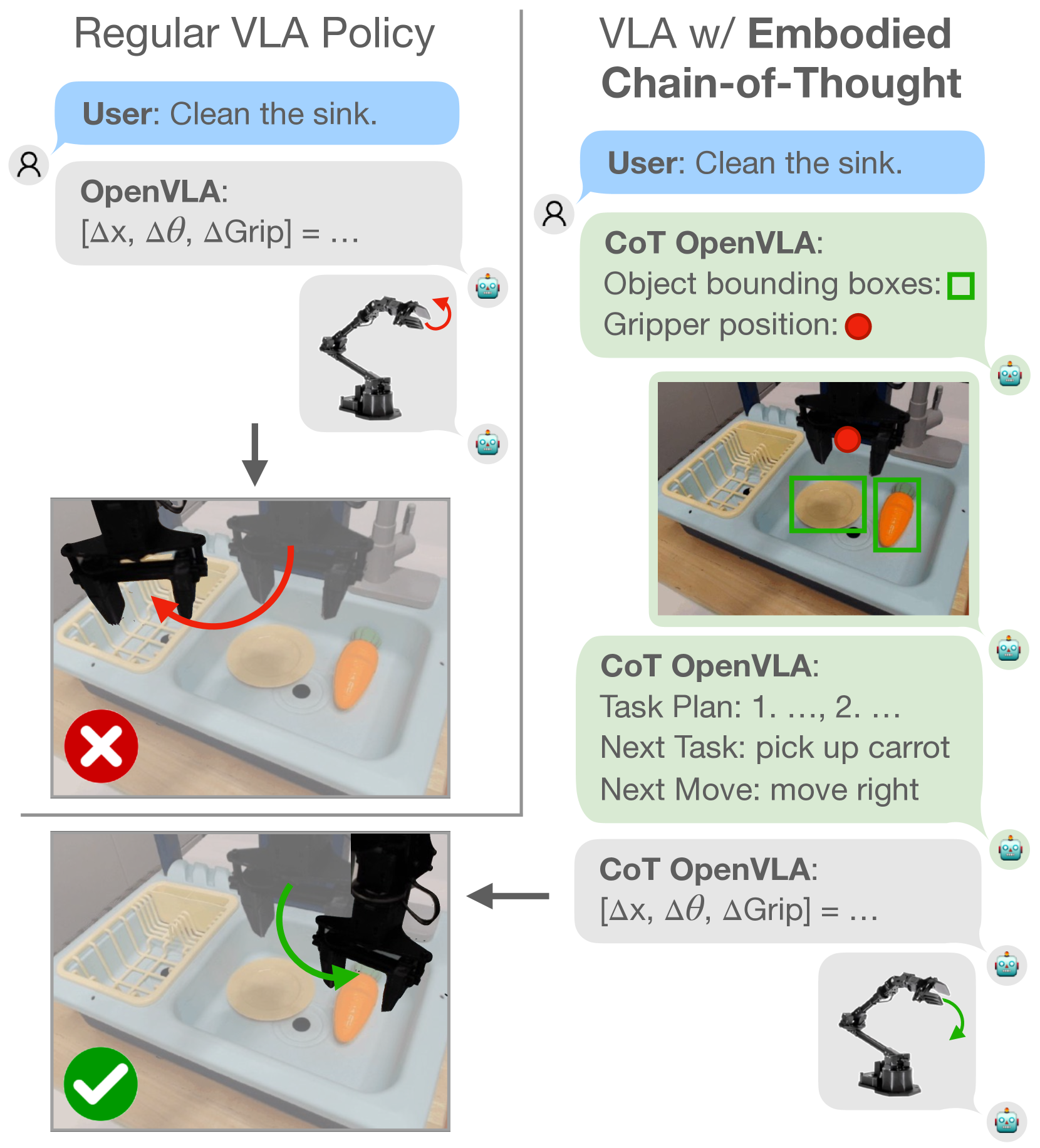
Conceptual flow of the ECoT policy inference.
Evaluation Highlights
- Increases absolute success rate of OpenVLA by 28% across challenging generalization tasks (new objects, scenes, viewpoints) without new robot data
- Outperforms RT-2-X (55B parameter model trained on significantly more data) using only a 7B parameter model and the Bridge V2 dataset
- Enables human correction via natural language feedback, boosting success rates on hard tasks by 48% (absolute) compared to uncorrected performance
Breakthrough Assessment
9/10
Demonstrates a massive performance jump (+28%) by adding reasoning tokens, effectively bridging the gap between high-level LLM reasoning and low-level control while enabling interpretable human correction.