📝 Paper Summary
Interpretability of Large Reasoning Models (LRMs)
Reasoning chain analysis
DeepSeek-R1's visible reasoning chains reveal a structured process of 'blooming' and 'reconstruction', where excessive re-verification (rumination) on complex problems often signals inefficiency rather than improved accuracy.
Core Problem
Large Reasoning Models (LRMs) like o1 are typically opaque, preventing researchers from understanding how reasoning chains (thoughts) are structured, whether longer thinking is beneficial, or if the process introduces safety risks.
Why it matters:
- Inference-time scaling assumes longer thinking yields better answers, but the limits of this scaling are unknown
- Understanding the internal 'thought' structure is crucial for diagnosing why models fail or behave erratically in long contexts
- Hidden reasoning processes may harbor safety vulnerabilities or cultural biases that bypass standard alignment filters
Concrete Example:
In a math problem about letter writing (Figure 1.2), GPT-4o linearly calculates an answer. DeepSeek-R1 generates a long chain: it solves it, then triggers a 'Wait' step to re-verify the number of weeks in a year, explores an alternative interpretation of 'twice a week', and only then concludes. This transparency allows analysis of 'rumination'.
Key Novelty
Thoughtology: A Taxonomy of LRM Reasoning
- Proposes a structural taxonomy for reasoning chains: Problem Definition → Blooming (initial solution) → Reconstruction (re-verification loops) → Final Decision
- Identifies 'Rumination': a phenomenon where the model redundantly re-verifies the same assumptions multiple times without diverse exploration, resembling a cognitive loop
- Demonstrates a 'sweet spot' for reasoning length, showing that enforcing longer thoughts beyond a problem-specific threshold can degrade performance
Architecture
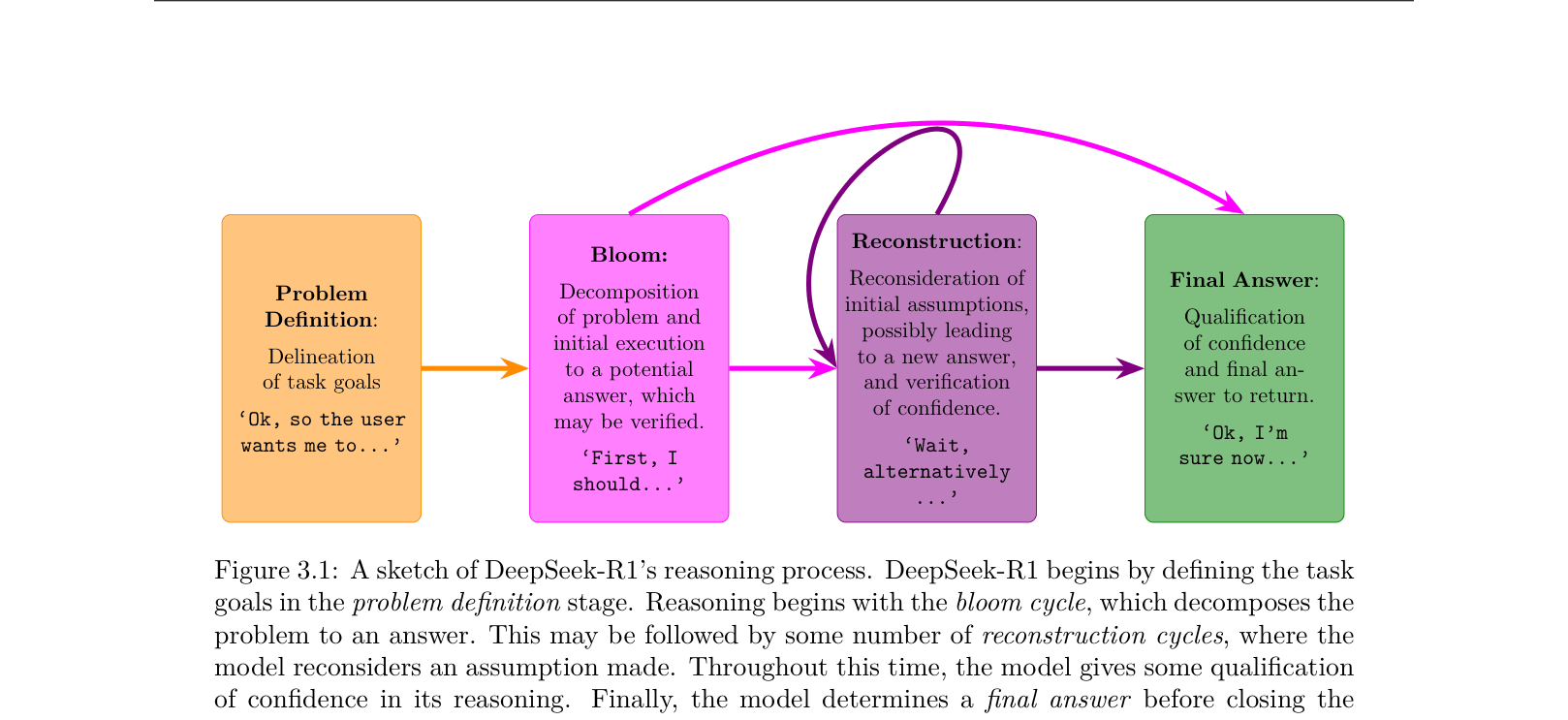
A taxonomy of DeepSeek-R1's reasoning process, breaking it down into four distinct stages.
Evaluation Highlights
- Analysis of 400 annotated reasoning chains reveals a consistent 'Bloom and Reconstruct' cycle across math, safety, and context tasks
- DeepSeek-R1 creates longer reasoning chains for English prompts compared to Chinese prompts for the same moral/cultural questions
- Increasing problem complexity correlates with higher 'rumination' rates (higher 5-gram repetition, lower lexical diversity) rather than diverse exploration
Breakthrough Assessment
8/10
While primarily an analysis paper, it provides the first systematic taxonomy and 'Thoughtology' framework for an open-weights LRM (DeepSeek-R1), challenging the assumption that longer inference always equals better reasoning.