📊 Experiments & Results
Evaluation Setup
Evaluation across diverse domains (Math, Programming, General) using Qwen-2.5 models.
Benchmarks:
- General Tasks (Conversational/Factual)
- Mathematics (Reasoning)
- Programming (Code Generation)
Metrics:
- Hybrid Accuracy (H_Acc)
- Downstream task performance (Accuracy/Pass@k)
- Efficiency (Token consumption/Latency)
- Statistical methodology: Not explicitly reported in the paper
Experiment Figures
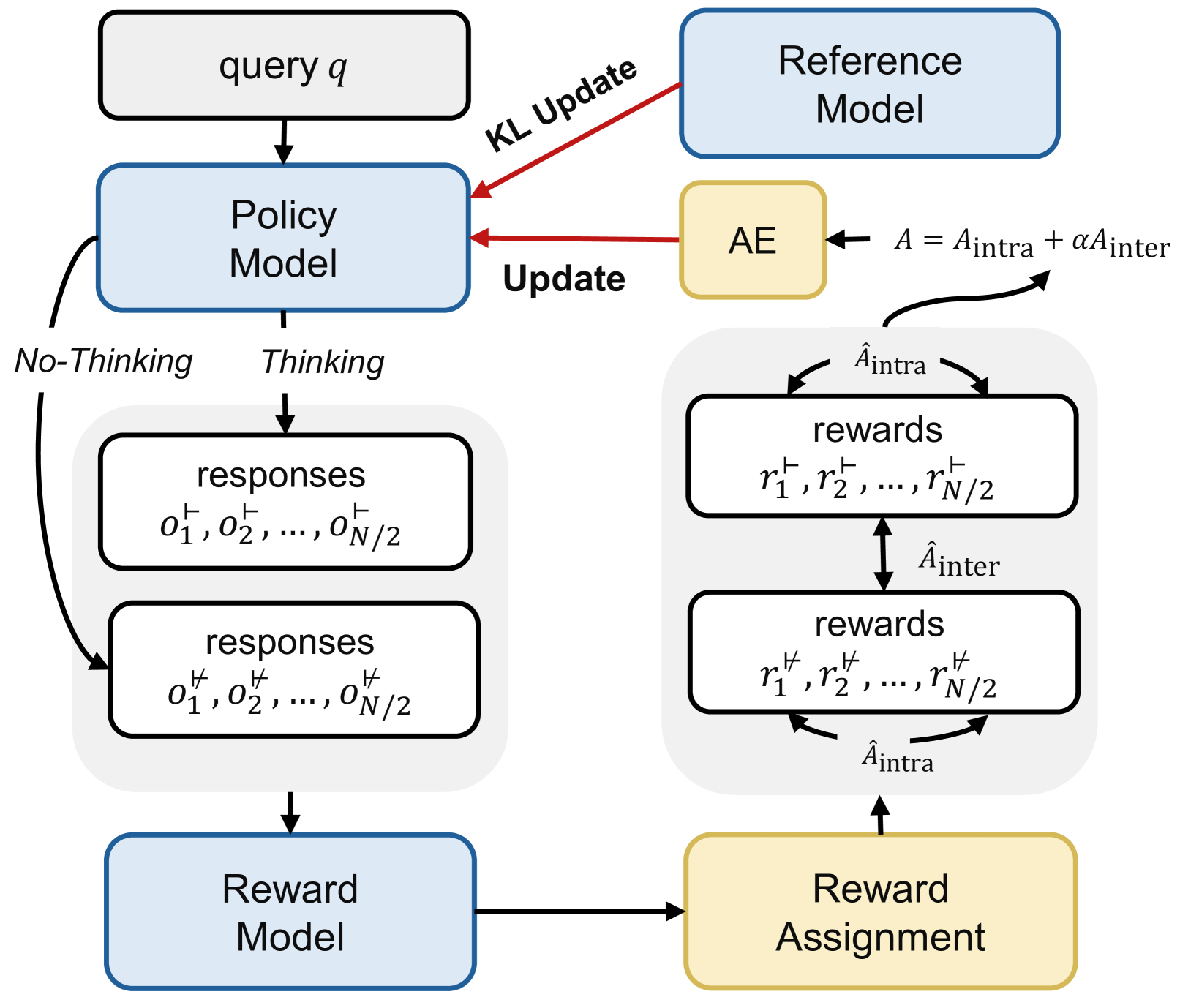
Illustration of the Hybrid Group Policy Optimization (HGPO) training process.
Main Takeaways
- LHRMs successfully learn to switch modes: engaging thinking for complex math/code and skipping it for simple greetings/facts.
- The Hybrid Accuracy metric is validated as a robust proxy for human judgment regarding when thinking is necessary.
- Efficiency is significantly improved compared to standard LRMs because the model avoids generating long reasoning chains for trivial queries.
- General capability allows the model to serve as a 'one-size-fits-all' solution, replacing the need for separate models for simple vs. complex tasks.