📝 Paper Summary
Reasoning LLMs
Inference Efficiency
Test-time Compute
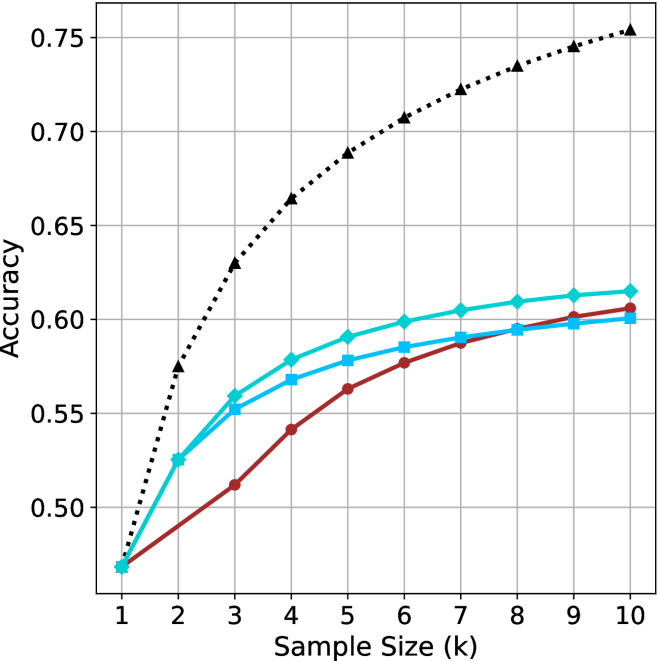
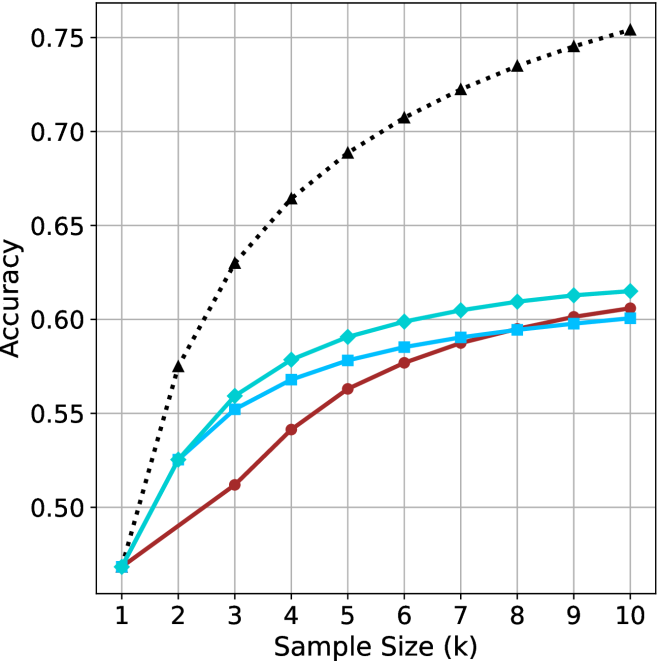
Selecting shorter reasoning chains from parallel generations consistently outperforms standard majority voting and longer chains while reducing computational cost and latency.
Core Problem
Current reasoning LLMs rely on scaling test-time compute by generating long thinking chains, which incurs high computational costs and latency without necessarily guaranteeing correctness.
Why it matters:
- The assumption that longer thinking equals better reasoning drives massive increases in inference cost and energy consumption.
- Slow decoding times due to long autoregressive chains hinder real-time applications of reasoning models.
- Existing methods like majority voting waste resources on long, often incorrect trajectories.
Concrete Example:
When a model generates 20 solutions for a math problem, the longest chain might backtrack excessively and halluncinate, while a much shorter chain reaches the correct answer directly. Standard majority voting treats them equally or favors the more numerous (potentially long) errors, whereas the proposed method picks the short one.
Key Novelty
short-m@k Inference Strategy
- Run k parallel generations but strictly halt all computation as soon as the first m trajectories finish (where m is small, e.g., 1 or 3).
- Select the final answer via majority vote among only these shortest m completed chains (breaking ties by length).
- Leverages the empirical finding that for a specific question, correct reasoning chains are typically shorter than incorrect ones.
Architecture
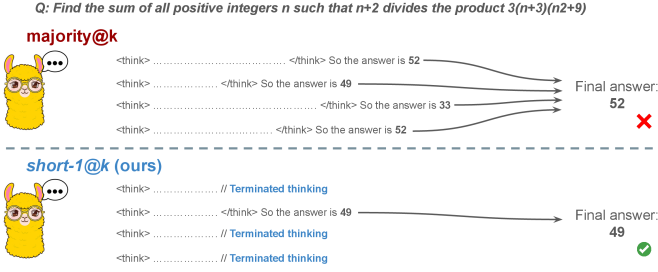
Visualization of the short-m@k inference process compared to standard approaches.
Evaluation Highlights
- Choosing the shortest chain outperforms the longest chain by up to 34.5% accuracy on math benchmarks.
- short-1@k matches majority voting performance while reducing compute by up to 40% on LN-Super-49B.
- short-3@k consistently outperforms majority voting across all compute budgets while reducing wall time by up to 33%.
Breakthrough Assessment
8/10
Challenges the prevailing 'more compute/longer thinking is better' paradigm with strong empirical evidence. Offers a simple, practical inference method that improves both speed and accuracy.