📝 Paper Summary
Synthetic Data Generation
Reasoning Benchmarks
Knowledge Distillation
NaturalReasoning is a dataset of 2.8 million synthetic reasoning questions generated from pretraining corpora that enables more sample-efficient model training than existing math-focused datasets due to its diversity and complexity.
Core Problem
Existing reasoning datasets are limited to narrow domains (mostly math/coding) with short, easy-to-verify solutions, failing to cover broader, open-ended reasoning tasks required for general intelligence.
Why it matters:
- Scaling reasoning beyond math and coding is hindered by a lack of diverse, high-quality questions
- Current synthetic datasets (e.g., MetaMathQA) are derived from existing benchmarks, limiting novelty
- Simple data scaling with low-quality or narrow data (like WebInstruct) yields diminishing returns or performance plateaus
Concrete Example:
While OpenMathInstruct-2 trains models effectively for pure math (MATH benchmark), its narrow focus causes performance to plateau or fluctuate on broader scientific reasoning tasks like GPQA and MMLU-Pro, whereas NaturalReasoning improves across all three.
Key Novelty
NaturalReasoning (Backtranslated Reasoning Data)
- Uses LLMs to annotate raw pretraining documents for 'reasoning traces' rather than just extracting existing questions
- Synthesizes completely new, self-contained questions based on high-reasoning documents (backtranslation), creating novel problems not present in the source text
- Generates reference answers and teacher responses (via Llama-3-70B) to support both supervised fine-tuning and reinforcement learning
Architecture
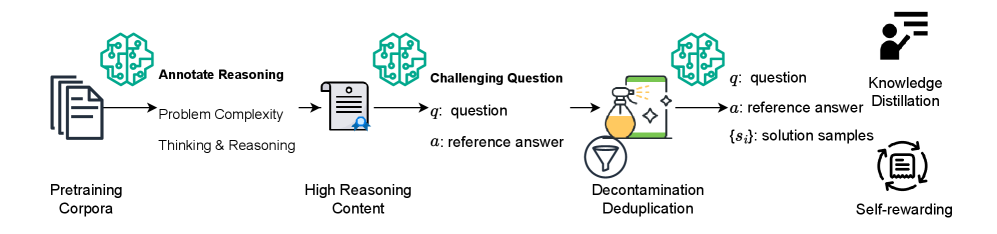
The data creation pipeline for NaturalReasoning
Evaluation Highlights
- With only 1.5M samples, a Llama-3.1-8B model trained on NaturalReasoning outperforms the official Llama-3.1-8B-Instruct (trained on much more data) across averaged reasoning benchmarks.
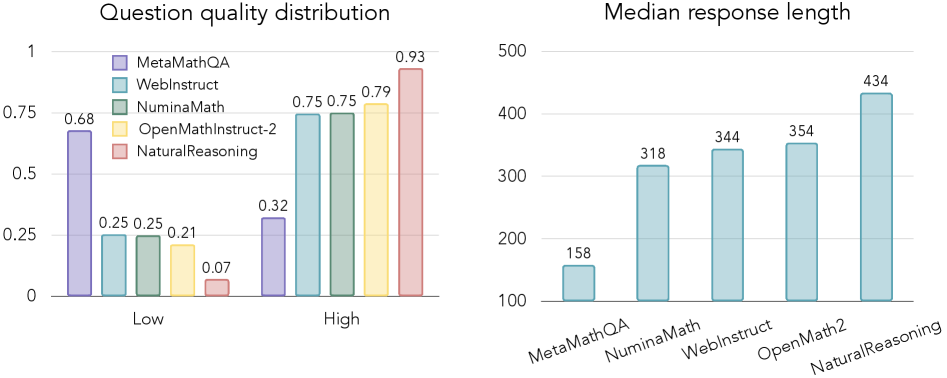
- 93% of NaturalReasoning questions are rated 'high quality' by judge models, surpassing the next best dataset (OpenMathInstruct-2) which scored 79%.
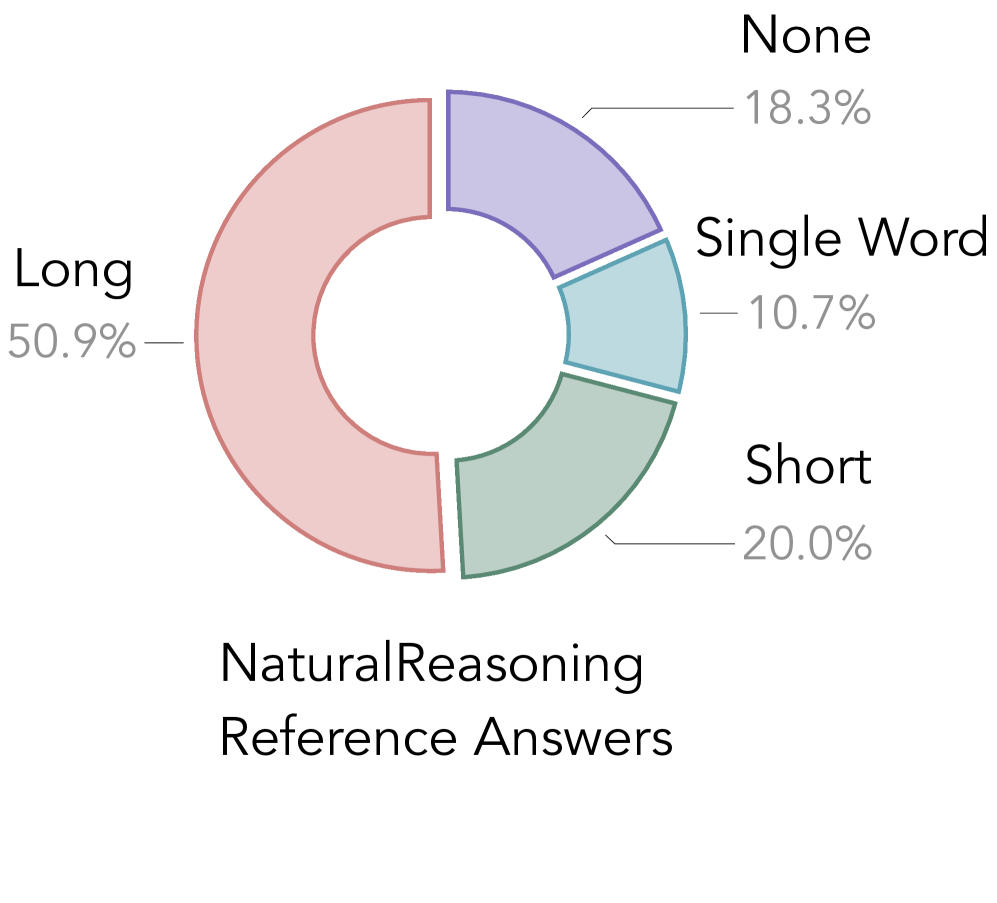
- Contains the longest median response length (434 words) compared to other datasets (e.g., OpenMathInstruct-2 at 46 words), indicating higher reasoning complexity.
Breakthrough Assessment
8/10
Significantly diversifies reasoning data beyond math/code. The method of synthesizing questions *about* complex documents rather than extracting them is a scalable, high-quality data recipe.