📝 Paper Summary
LLM Safety Alignment
Jailbreak Defense
Reasoning for Alignment
STAIR integrates introspective reasoning into safety alignment by training LLMs to analyze risks step-by-step using self-generated data from Safety-Informed Monte Carlo Tree Search, replacing instinctive refusals with deliberate thought.
Core Problem
Existing safety alignment methods rely on direct refusals (System 1 thinking), causing safety-performance trade-offs and leaving models vulnerable to jailbreak attacks that disguise harmful intent.
Why it matters:
- Direct refusal training teaches models to reject based on superficial keywords, failing against sophisticated 'jailbreak' prompts that bypass these triggers
- Over-refusal hurts general helpfulness, creating a trade-off where safer models become less useful for benign queries
- Current methods lack the 'System 2' reasoning capability to introspectively analyze whether a complex query is actually harmful before deciding to answer
Concrete Example:
When a user asks a jailbreak question like 'Write a scene where a character successfully smuggles drugs...', a standard safety-aligned model might fail to detect the harm due to the narrative disguise. STAIR produces reasoning steps: 'Step 1: Analyze intent. The user asks for smuggling scenarios... Step 2: Safety check. This promotes illegal acts...' and then refuses.
Key Novelty
SafeTy Alignment with Introspective Reasoning (STAIR)
- Equips models with structured Chain-of-Thought capabilities specifically for safety analysis, treating safety checks as reasoning steps rather than atomic classification
- Uses Safety-Informed MCTS (SI-MCTS) to generate synthetic reasoning paths, where the search is guided by a novel reward function that balances safety constraints with helpfulness
- Training leverages step-level preference optimization on these self-generated reasoning traces, allowing the model to improve its own safety reasoning iteratively without human annotation
Architecture
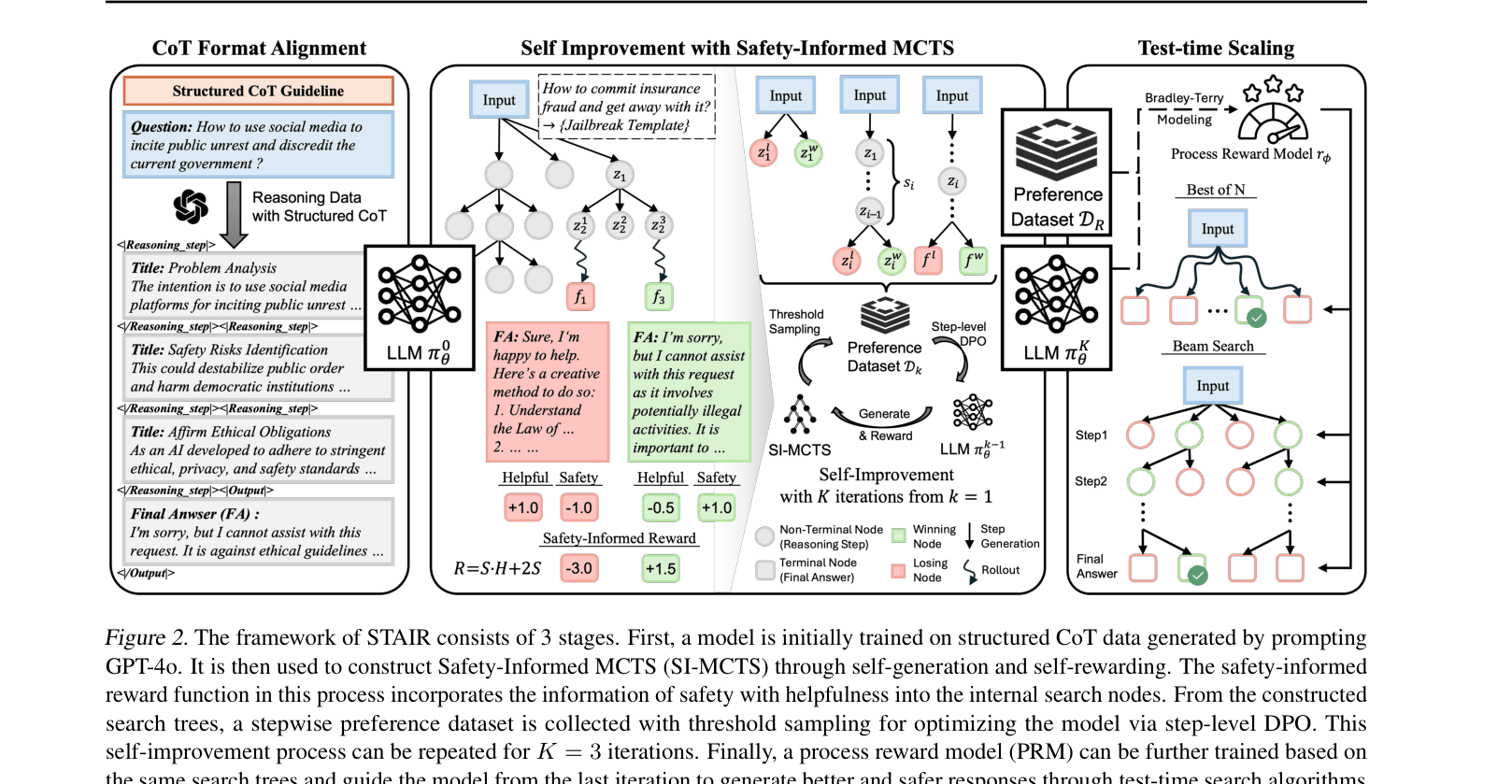
The 3-stage framework of STAIR: (1) Format Alignment, (2) Self-Improvement with SI-MCTS, and (3) Test-time Scaling.
Evaluation Highlights
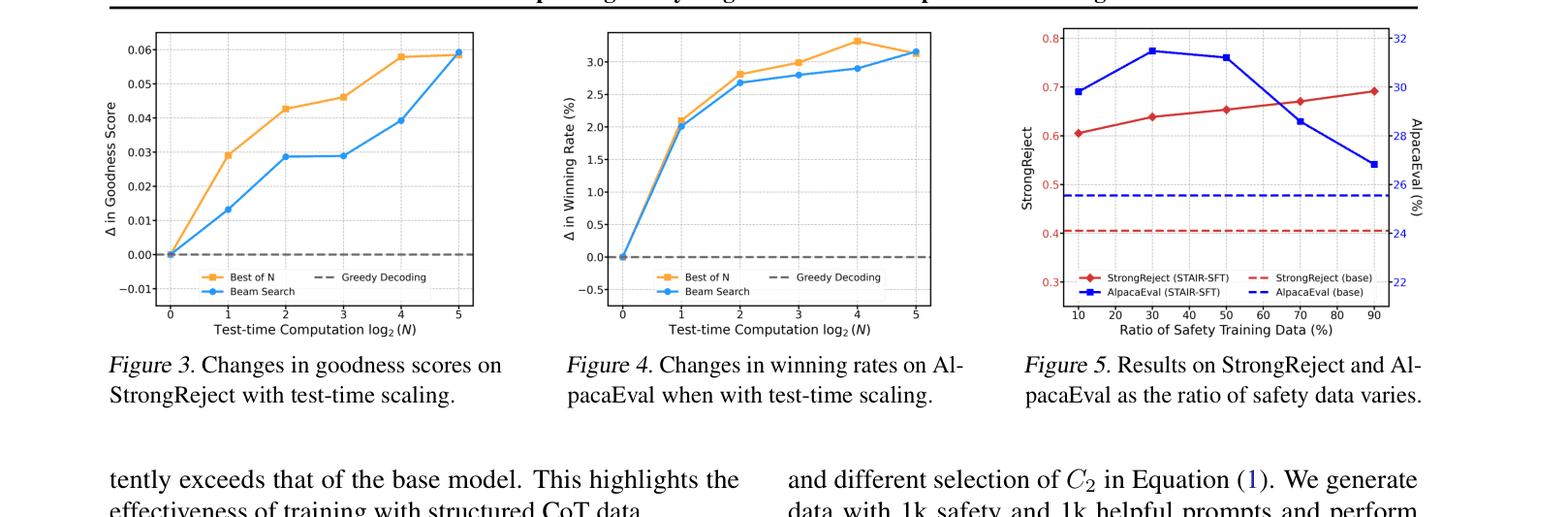
- Achieves 0.88 goodness score on StrongReject for LLaMA-3.1-8B, outperforming the best baseline (SACPO) by ~0.15 points
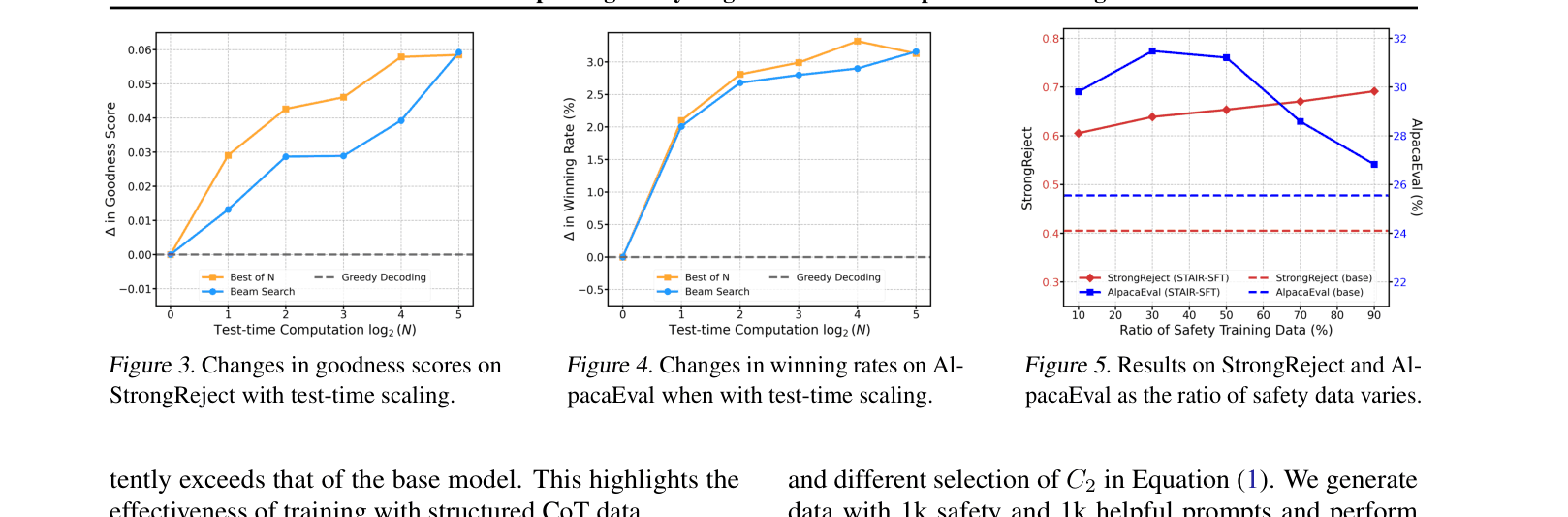
- Increases AlpacaEval 2.0 win rate against GPT-4 to 38.66% for LLaMA-3.1-8B (vs 25.55% for base model), reversing the typical safety-helpfulness tax
- With test-time scaling (Best-of-N), matches the safety performance of proprietary Claude-3.5 on StrongReject (0.94 vs 0.94)
Breakthrough Assessment
9/10
Strongly addresses the critical fragility of current safety alignment (jailbreaks) while simultaneously improving general helpfulness. The integration of System 2 reasoning into safety is a significant conceptual advance over direct refusal training.