📝 Paper Summary
Reinforcement Learning for Reasoning
LLM Reasoning
Verifier-Free Training
VeriFree extends DeepSeek-R1-Zero-style reasoning training to general domains by replacing external verifiers with a likelihood-based objective that treats the correct answer as a probabilistic target given a generated chain of thought.
Core Problem
DeepSeek-R1-Zero-style reinforcement learning relies on rule-based verifiers (valid for math/code), but cannot extend to general domains (law, chemistry) where verification is hard, often forcing reliance on slow, exploitable model-based verifiers.
Why it matters:
- Rule-based verification is impossible for many real-world tasks (e.g., 'What is the capital of France?' cannot be executed like code).
- Using a separate LLM as a verifier (reward model) is computationally expensive, memory-intensive, and prone to reward hacking.
- Existing variational approaches for latent reasoning (like JLB or LaTRO) underperform standard R1-Zero methods.
Concrete Example:
In a math problem, a rule-based verifier checks if 'boxed{8/5}' equals '1.6'. In a chemistry question asking 'Which element...', no simple rule exists. Standard approaches would require a heavy second LLM to judge correctness, whereas VeriFree computes the probability of the ground truth token directly from the policy.
Key Novelty
Verifier-Free (VeriFree) Policy Optimization
- Treats the reasoning trace as a latent variable and optimizes the policy to maximize the likelihood of the ground-truth answer given that trace.
- Derives a gradient estimator that is mathematically equivalent to standard RL with a perfect verifier (assuming a unique correct answer) but has analytically lower variance via Rao-Blackwellization.
- Eliminates the need for a separate reward model or rule-based checker by using the policy itself to score the consistency between its reasoning and the reference answer.
Architecture
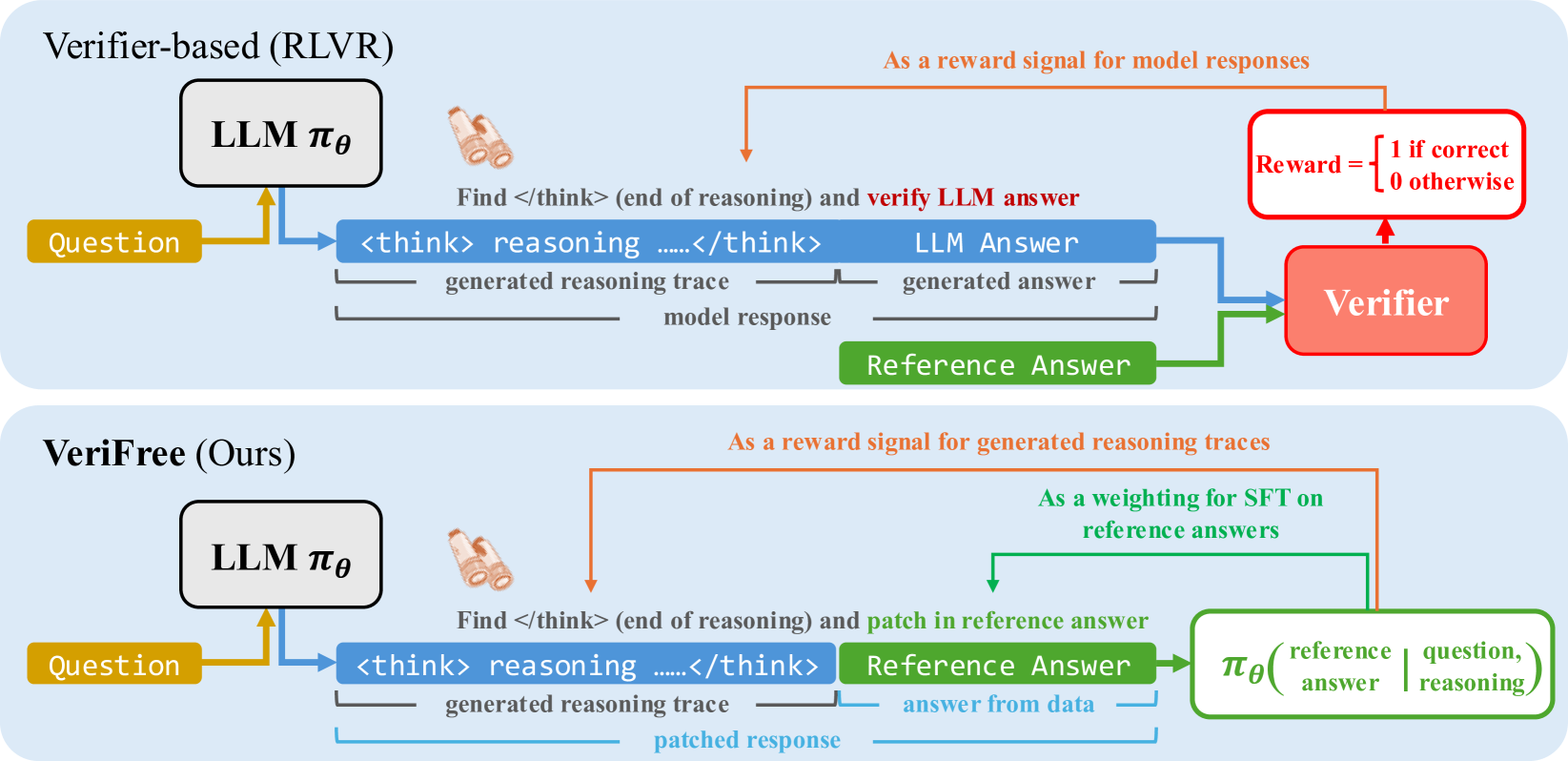
Comparison of Standard RLHF/RLVR pipeline versus the proposed VeriFree pipeline.
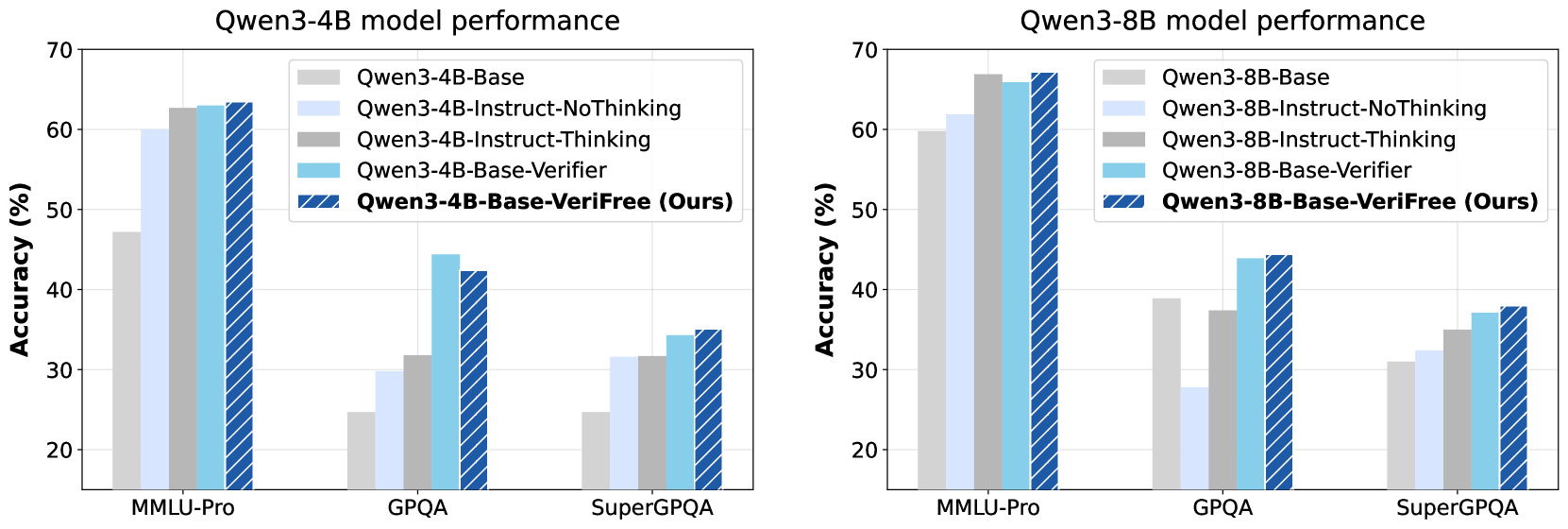
Evaluation Highlights
- Outperforms verifier-based RL baselines on general reasoning benchmarks: +3.0% accuracy on MMLU-Pro compared to RL with a learnt verifier.
- Matches or exceeds performance on math tasks where verifiers exist: +1.2% on MATH benchmark compared to standard R1-Zero style training.
- Achieves these gains with significantly reduced compute and memory overhead by removing the need for an external verifier model during training.
Breakthrough Assessment
8/10
Elegantly solves the 'verification bottleneck' for general reasoning. By proving equivalence to RLVR with lower variance, it enables R1-style reasoning gains in non-formal domains without the cost/fragility of reward models.