📊 Experiments & Results
Evaluation Setup
Reasoning evaluation on challenging Math and Code benchmarks using pass@1
Benchmarks:
- AIME 2024 / 2025 (Math Competitions)
- LiveCodeBench (v5) (Code Generation / Competitive Programming)
Metrics:
- Pass@1
- Pass@k (up to k=1024)
- Statistical methodology: Not explicitly reported in the paper
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| Math-only RL experiments demonstrate significant gains on Math benchmarks and unexpected cross-domain gains on Code benchmarks. | ||||
| AIME 2025 | Pass@1 | 46.1 | 60.7 | +14.6 |
| AIME 2025 | Pass@1 | 70.0 | 87.2 | +17.2 |
| LiveCodeBench v5 | Pass@1 | 37.6 | 44.4 | +6.8 |
| LiveCodeBench v5 | Pass@1 | 53.1 | 58.9 | +5.8 |
| Code-only RL (applied after Math RL) further boosts code scores with minimal degradation to math scores. | ||||
| LiveCodeBench v5 | Pass@1 | 44.4 | 48.7 | +4.3 |
| AIME 2025 | Pass@1 | 60.7 | 59.9 | -0.8 |
Experiment Figures
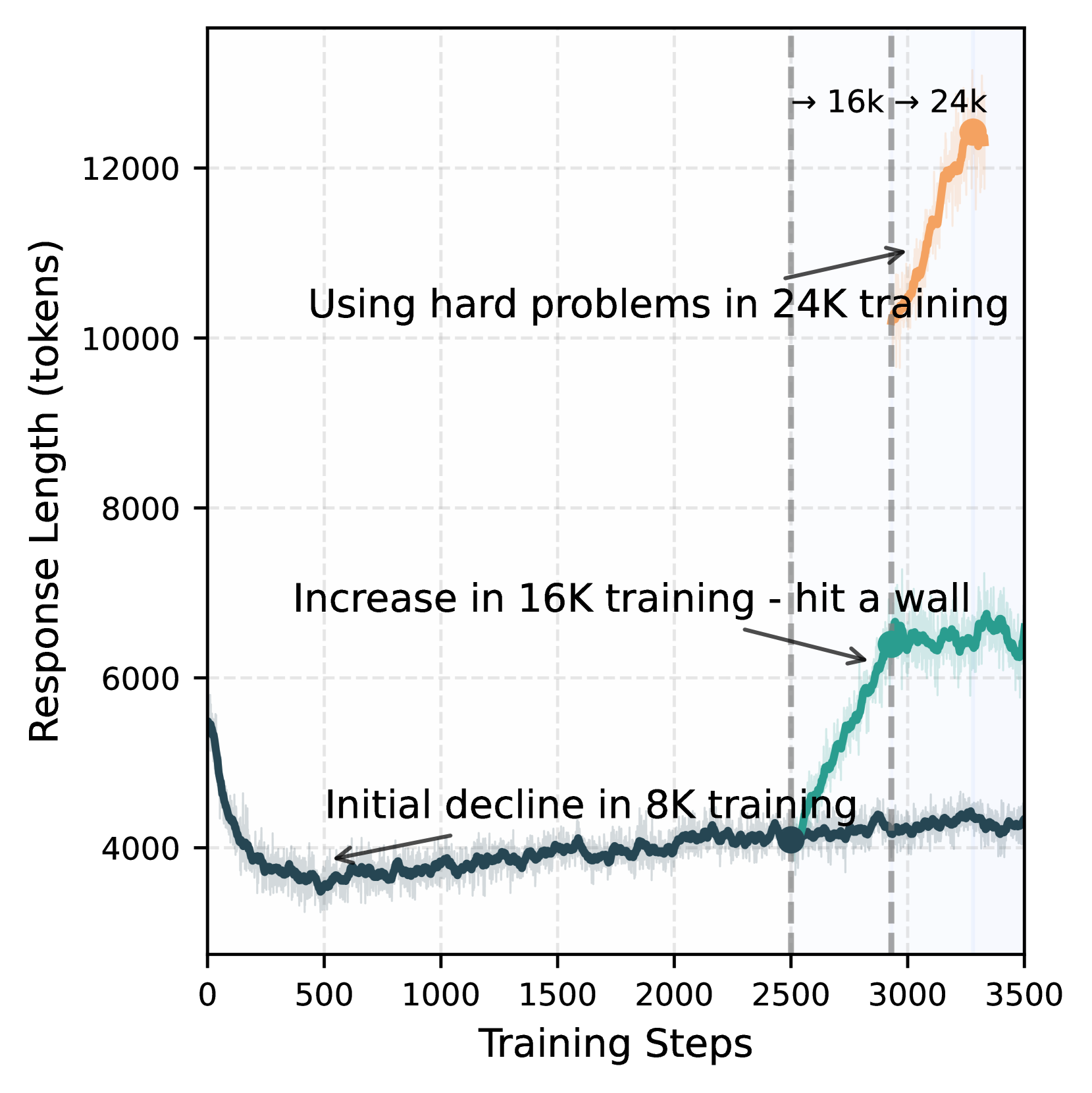
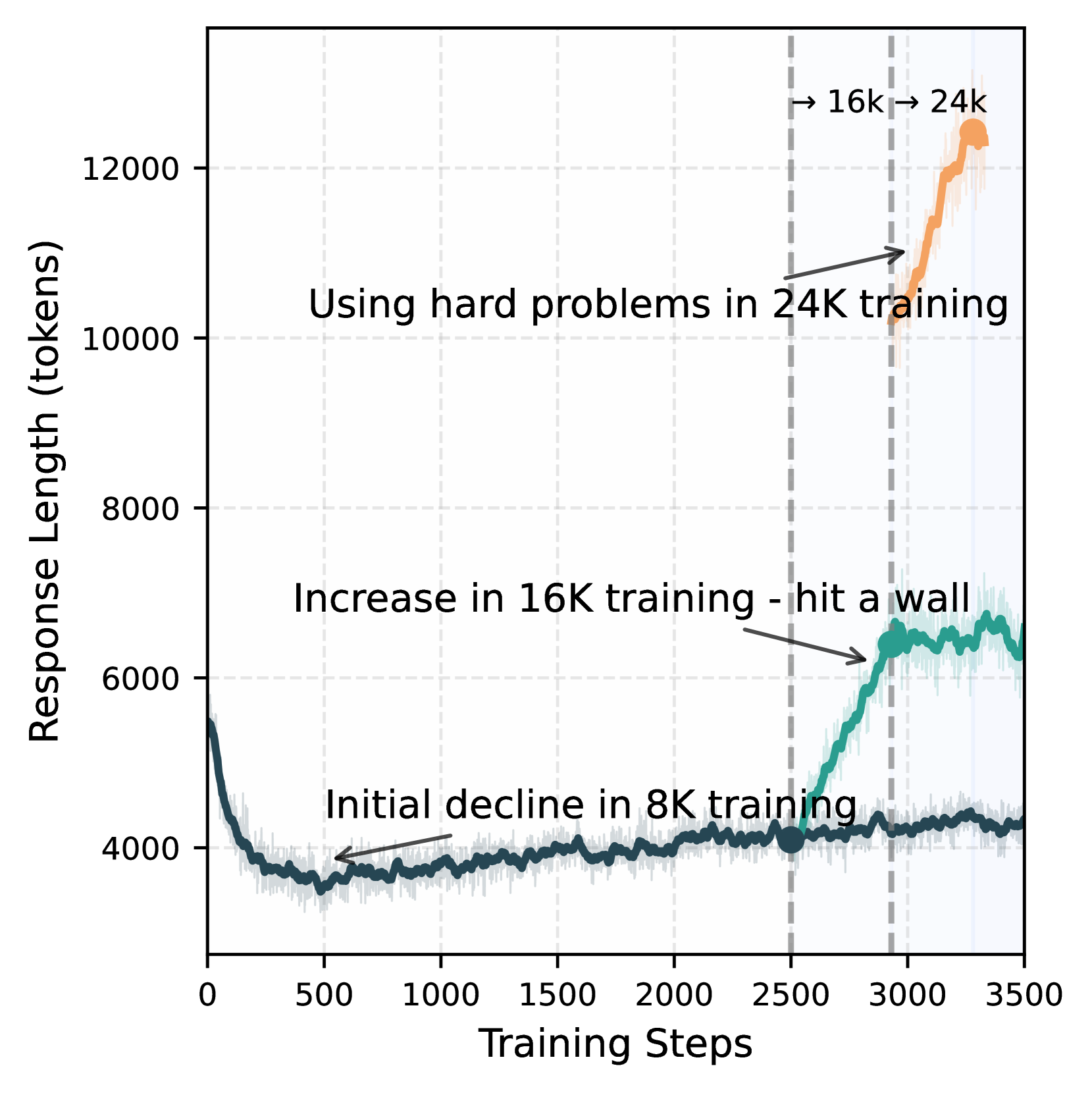
Impact of response length extension on AIME 2024 accuracy
Entropy curves for different gradient update strategies
Improvement in code pass rates across different topics after Math-only RL
Main Takeaways
- Large-scale RL is highly effective for enhancing reasoning in small/mid-sized distilled models, contrary to prior beliefs favouring pure distillation.
- Math-only RL acts as a foundational reasoning booster, improving performance even on code tasks (Cross-domain generalization).
- A sequential curriculum (Math RL → Code RL) prevents catastrophic forgetting, allowing the model to excel in both domains simultaneously.
- Strict on-policy updates (single gradient step per group) are crucial for preventing entropy collapse during training.