📝 Paper Summary
Multimodal GUI Agents
Vision-Language Navigation
InfiGUIAgent is a multimodal agent that learns native hierarchical planning and self-reflection skills through a two-stage fine-tuning process, reducing reliance on external accessibility trees.
Core Problem
Existing MLLM-based GUI agents struggle with multi-step reasoning (leading to repetitive errors) and rely heavily on text-based accessibility trees, which lose visual information and introduce computational overhead.
Why it matters:
- Reliance on textual representations (accessibility trees/Set-of-Marks) causes information loss and varies by platform, hindering deployment
- Lack of native reflection capabilities leads agents to repeat the same mistakes without self-correction during complex tasks
- Current agents lack robust fundamental skills in understanding high-resolution, clutter-heavy mobile and computer interfaces
Concrete Example:
Many agents rely on 'Set-of-Marks' (overlaying IDs on the screen) to interact. InfiGUIAgent instead processes the raw pixels directly to perform actions like clicking specific coordinates.
Key Novelty
Two-Stage SFT with Synthesized Native Reasoning
- Stage 1 SFT: Enhances fundamental grounding and understanding using standardized datasets (Screen2Words, Rico) with coordinate normalization.
- Stage 2 SFT: Instills 'native' reasoning by fine-tuning on trajectories synthesized by a teacher model (Qwen2-VL-72B) that include explicit hierarchical planning and expectation-reflection loops.
- Reflective Reasoning: The model is trained to generate an 'expectation' before an action and a 'reflection' after observing the result, enabling self-correction.
Architecture
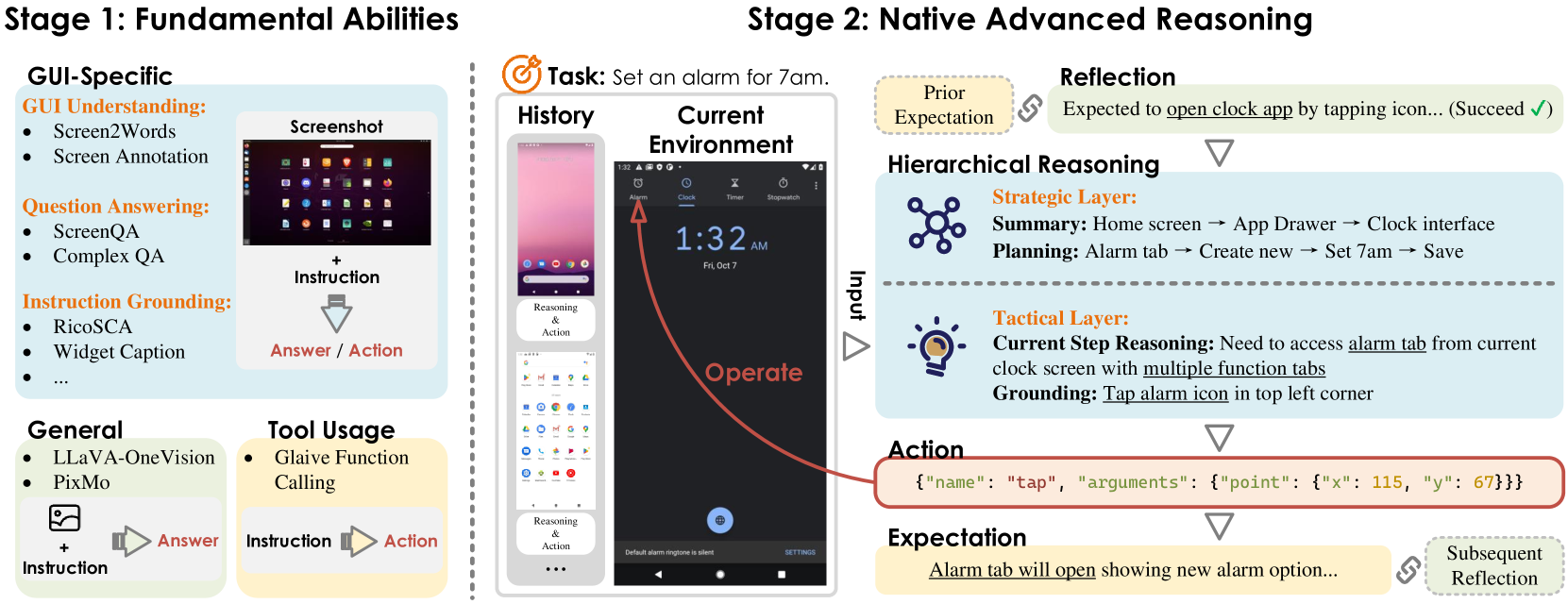
The two-stage supervised fine-tuning pipeline. Stage 1 focuses on Fundamental Abilities (Understanding, Grounding) using collected datasets. Stage 2 focuses on Native Reasoning (Hierarchical, Expectation-Reflection) using synthesized data from trajectories.
Evaluation Highlights
- Quantitative results are not contained in the provided text (the text provided ends at Section 3.2, before the Experiments section).
Breakthrough Assessment
7/10
Proposes a robust methodology for internalizing reasoning (vs. prompting) and removing dependency on accessibility trees, which is a significant architectural shift for GUI agents.