📝 Paper Summary
Reinforcement Learning for LLMs
Curriculum Learning
SEC treats curriculum selection as a non-stationary Multi-Armed Bandit problem where an agent dynamically selects problem categories based on the absolute advantage of the current policy.
Core Problem
Standard RL fine-tuning curricula are either static (random/heuristics) or computationally expensive (online filtering), failing to align problem difficulty with the model's evolving capabilities.
Why it matters:
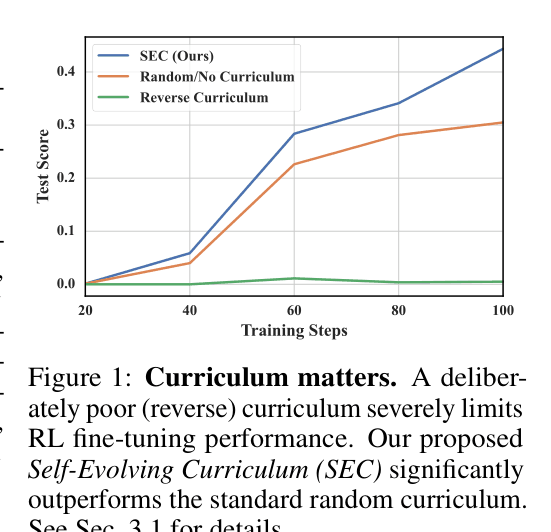
- Suboptimal curricula (like reverse difficulty) can severely stunt learning and generalization, as shown in controlled experiments
- Manual heuristics require human expertise and don't adapt to specific model progress
- Existing automatic methods often require expensive extra inference passes to estimate difficulty
Concrete Example:
In the Countdown game, a reverse curriculum (hard-to-easy) causes the model to fail completely on test sets (score ~0.0), whereas a random curriculum achieves ~0.4. Neither adapts to the model's actual competence.
Key Novelty
Self-Evolving Curriculum (SEC)
- Models curriculum selection as a Multi-Armed Bandit (MAB) problem where each arm is a problem category (e.g., difficulty level)
- Uses 'absolute advantage' from the RL policy update as a proxy for learning gain, avoiding expensive separate evaluation steps
- Updates curriculum probabilities on-the-fly using TD(0) to favor categories that currently yield the highest gradient updates
Architecture
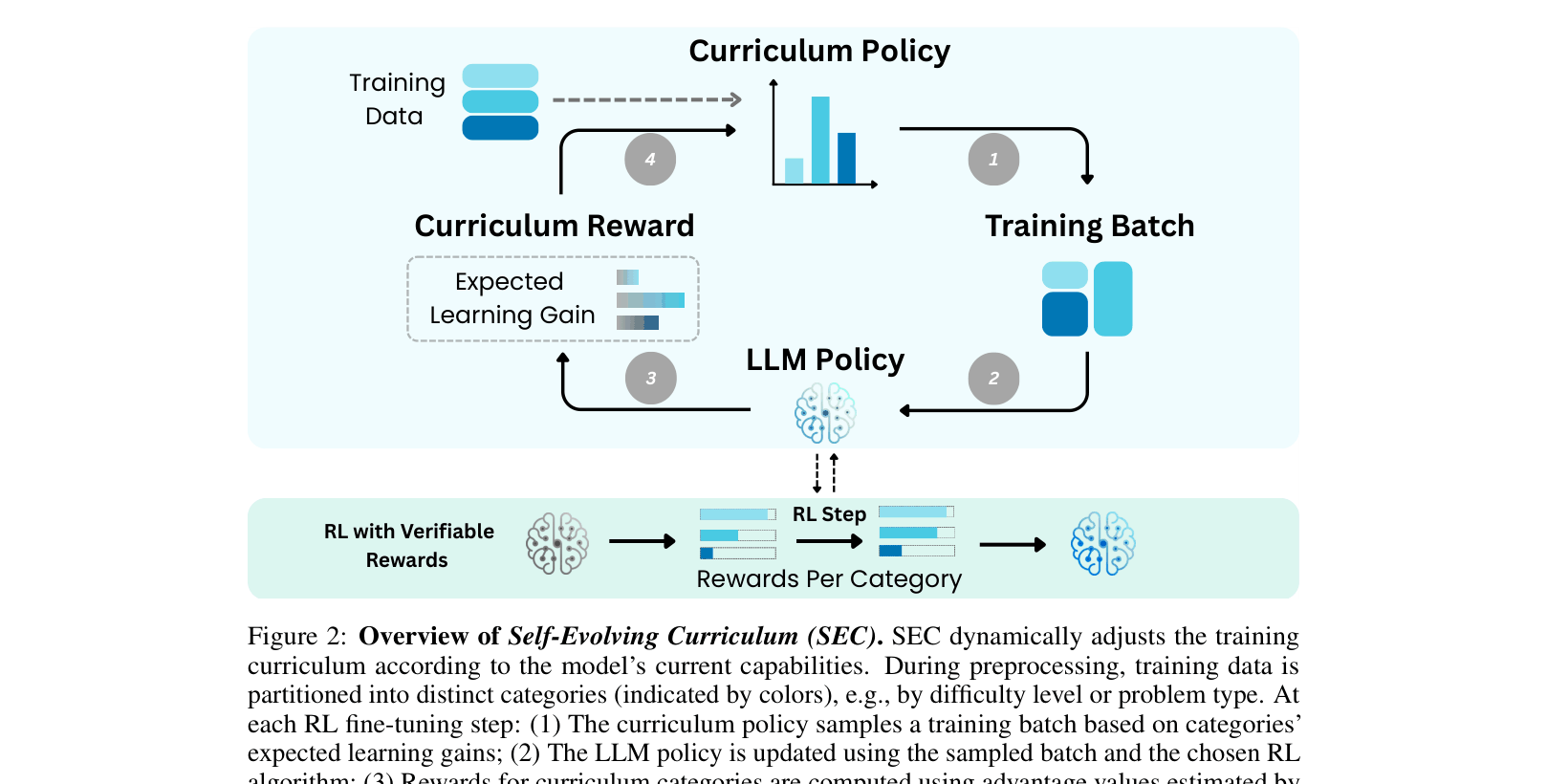
Overview of the Self-Evolving Curriculum (SEC) process loop during RL fine-tuning.
Evaluation Highlights
- +33% relative improvement on AIME24 math problems with Qwen2.5-3B compared to random curriculum
- +13% relative improvement on Countdown OOD tasks with Qwen2.5-3B compared to random curriculum
- Achieves stable multi-task learning (Countdown+Zebra+ARC), preventing the performance collapse seen with random curricula
Breakthrough Assessment
7/10
Strong empirical gains on reasoning tasks and a theoretically grounded, lightweight method. The reliance on predefined categories is a slight limitation, though addressed partially with automatic binning.