📝 Paper Summary
Efficient Reasoning
Chain-of-Thought (CoT) Optimization
NoWait improves reasoning efficiency by suppressing specific self-reflection tokens (like 'Wait' or 'Hmm') during inference, reducing redundant steps without compromising model accuracy.
Core Problem
Large Reasoning Models (LRMs) suffer from 'overthinking,' generating excessively verbose and redundant Chain-of-Thought trajectories characterized by self-reflection tokens like 'Wait' and 'Hmm,' which increases latency and compute costs.
Why it matters:
- Excessively long reasoning chains (thousands of tokens) create significant computational overhead and latency, hindering deployment in resource-constrained applications
- Current efficiency methods often require expensive retraining (RL with length penalties) or compromise model utility when simply truncating thoughts
Concrete Example:
In a math problem, a model might solve the equation, then generate 'Wait, let me double check...', entering a redundant validation loop that restates the same logic for hundreds of tokens before outputting the same answer.
Key Novelty
NoWait (Inference-time Keyword Suppression)
- Identifies a set of 'reflection keywords' (e.g., 'Wait', 'Alternatively') that signal the start of redundant self-verification loops
- Modifies the decoding process to set the probability (logits) of these specific tokens to negative infinity, preventing the model from initiating unnecessary self-reflection paths
- Forces the model to continue forward reasoning or conclude, pruning the 'Aha Moment' redundancy without altering model weights
Architecture
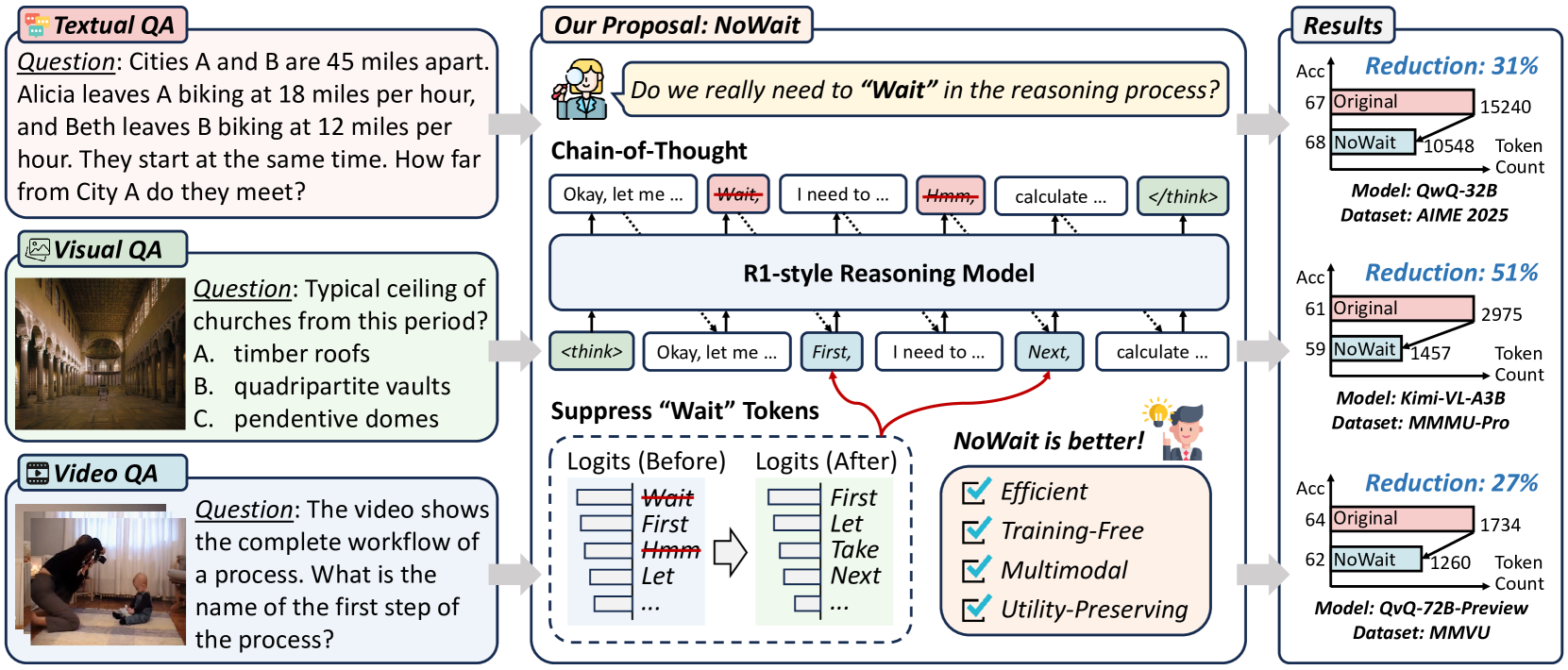
Illustration of the inference-time intervention where reflection keywords are suppressed.
Evaluation Highlights
- Reduces Chain-of-Thought trajectory length by 27%–51% across five R1-style model series (textual, visual, and video)
- Maintains or improves accuracy: QwQ-32B achieves +4.25% accuracy on AMC 2023 while reducing token count by ~30%
- Outperforms training-free baselines: On visual reasoning (MMMU, MathVista), reduces tokens by ~49% with only a 3.42% average accuracy drop, whereas prompt-based 'NoThink' causes severe degradation
Breakthrough Assessment
7/10
Simple, effective, plug-and-play solution to a timely problem (overthinking in R1-style models). While the technical novelty is low (logit masking), the empirical finding that 'thinking' tokens are largely redundant is significant.