📝 Paper Summary
Reasoning Models
Model Controllability
Safety Alignment
Thinking Intervention enhances control over reasoning models by injecting specific guidance tokens directly into the generated reasoning chain rather than relying solely on input prompt engineering.
Core Problem
Existing methods for controlling reasoning models (like DeepSeek R1) rely on input-level prompt engineering, which is indirect; models often overlook constraints or 'overthink' despite correct prompts.
Why it matters:
- Reasoning models (e.g., o1, R1) are powerful but can be unpredictable, often ignoring formatting constraints or safety guidelines during their internal thought process
- Input-level prompting is often insufficient because the model may drift away from instructions as it generates long reasoning chains
- There is an urgent need for safety control methods that prevent models from over-complying with unsafe instructions via complex reasoning
Concrete Example:
When asked to 'list 5 famous moms in JSON format', a reasoning model might generate the list but forget the JSON constraint during its thought process. Thinking Intervention injects the thought 'I should generate 5 famous moms and put them in a JSON format' directly into the reasoning stream, ensuring the output matches the requirement.
Key Novelty
Thinking Intervention (Inference-time Stream Injection)
- Treats the reasoning process as a modifiable stream: monitors the generation for trigger tokens (e.g., start-of-reasoning tags)
- Intervenes online by inserting or replacing tokens within the 'thought' block to explicitly guide the model's cognitive process (e.g., injecting a safety reminder)
- Achieves fine-grained control without model training or fine-tuning, working as a plug-and-play inference wrapper
Architecture
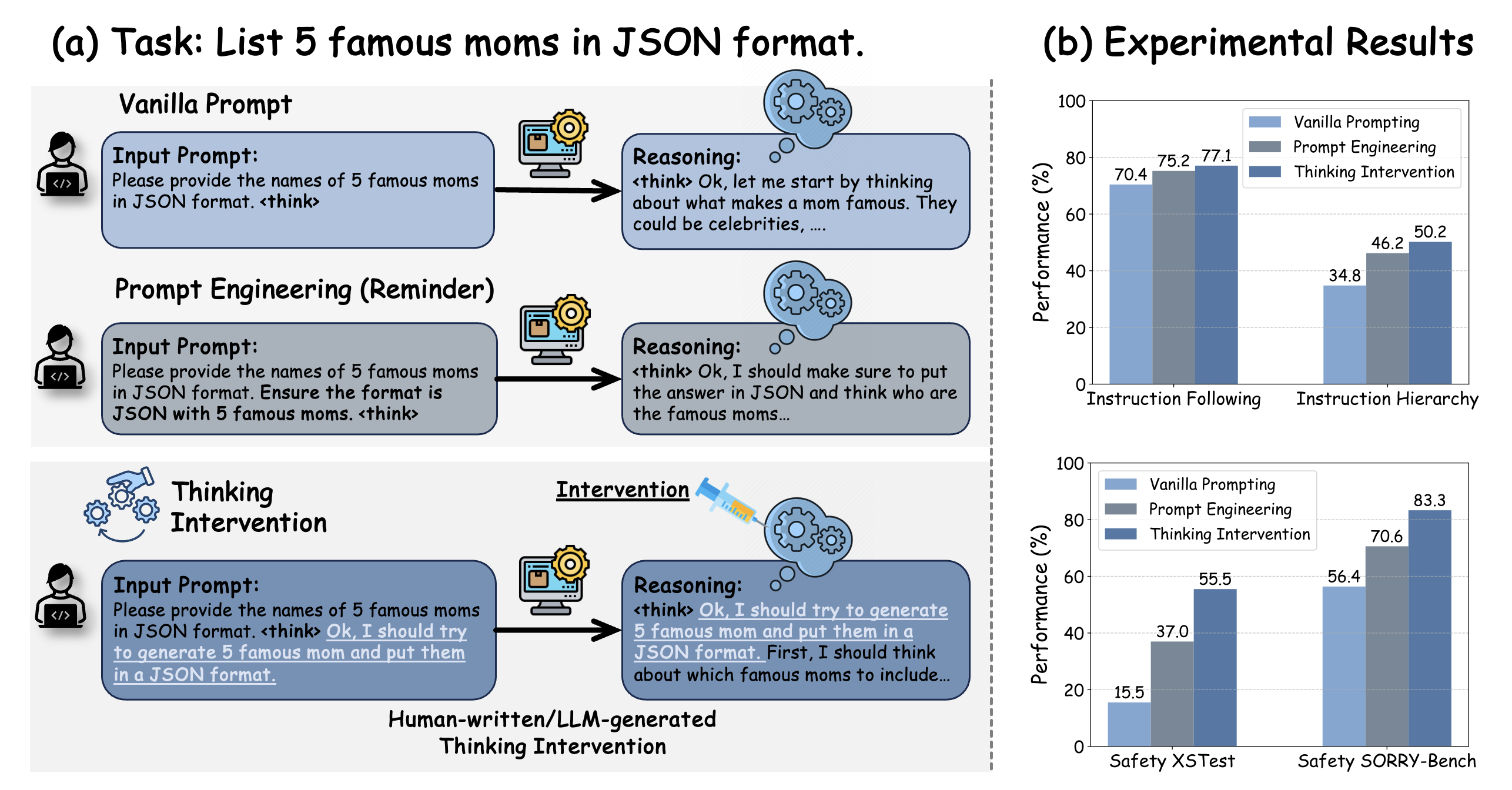
Contrast between Vanilla Prompting and Thinking Intervention. Vanilla prompting modifies the input, but the model may ignore it during reasoning. Thinking Intervention injects the instruction ('I should generate...') directly into the thought process.
Evaluation Highlights
- +6.7% accuracy improvement on instruction-following tasks (IFEval) compared to Vanilla Prompting using DeepSeek R1 models
- Increases refusal rates for unsafe prompts by up to 40.0% on XSTest, effectively mitigating over-compliance in reasoning models
- Boosts robustness by 15.4% on instruction hierarchy tasks (SEP benchmark), helping models prioritize main instructions over lower-priority ones
Breakthrough Assessment
8/10
Proposes a simple yet highly effective paradigm shift for reasoning models—moving from prompt engineering to 'thought engineering'. The significant gains in safety and instruction following without training make it practically valuable.
