📝 Paper Summary
Self-evolving LLMs
Reasoning
R-Zero is a framework that trains a language model to self-evolve by splitting it into a Challenger that generates difficult questions and a Solver that learns to answer them, without any human-labeled data.
Core Problem
Training advanced reasoning models typically requires vast amounts of expensive, human-curated data, creating a bottleneck for scaling intelligence beyond human limits.
Why it matters:
- Human annotation is costly, labor-intensive, and hard to scale for superintelligence
- Existing self-improvement methods often still rely on seed data or external verifiers (like code executors) which limits applicability in open-ended domains
Concrete Example:
A standard self-instruction method might generate random math problems that are either trivial or impossible to verify. R-Zero's Challenger specifically targets the 'edge' of the Solver's ability, ensuring the generated questions are solvable but difficult, driving actual learning.
Key Novelty
Co-evolving Challenger-Solver Framework
- Initializes two identical models: a Challenger (question generator) and a Solver (question answerer)
- The Challenger is rewarded for creating questions that cause high uncertainty (disagreement) in the Solver, targeting the frontier of the model's capability
- The Solver is rewarded for correctly answering these self-generated questions using majority-vote pseudo-labels, creating a self-sustaining curriculum
Architecture
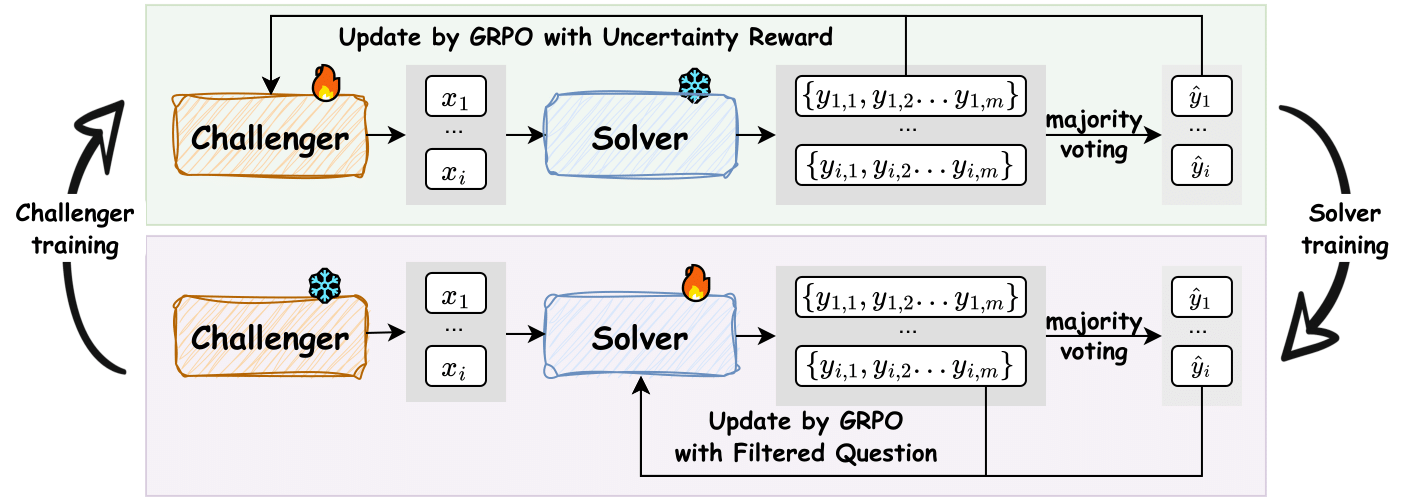
The iterative training loop of the R-Zero framework.
Evaluation Highlights
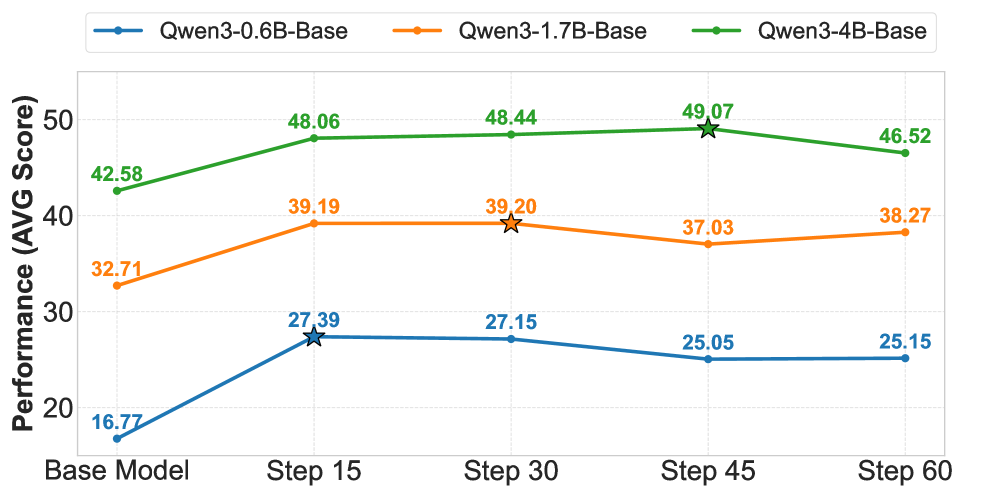
- +6.49 average score improvement on math benchmarks for Qwen3-4B-Base after three iterations
- +7.54 improvement on general-domain reasoning benchmarks for Qwen3-4B-Base, showing generalization beyond math
- +2.35 points gain over standard supervised fine-tuning when R-Zero is used as a mid-training step before fine-tuning
Breakthrough Assessment
8/10
Strong empirical results showing self-evolution from zero data is possible and effective. The co-evolution dynamic is well-motivated, though the observed performance collapse after multiple iterations suggests stability issues remain.