📝 Paper Summary
Reinforcement Learning for Reasoning
Efficient Inference
Chain-of-Thought (CoT) Optimization
S-GRPO modifies the Group Relative Policy Optimization algorithm by sampling serial early-exit points within a single reasoning path and assigning decaying rewards to earlier correct answers, encouraging concise and accurate thought processes.
Core Problem
Current reasoning models often exhibit 'overthinking,' generating redundant or irrelevant intermediate steps that inflate computation costs without improving accuracy.
Why it matters:
- Redundant reasoning steps significantly increase inference latency and computational overhead
- Existing outcome-reward RL methods (like GRPO) only reward the final answer, failing to penalize inefficient intermediate steps
- Excessive thinking can sometimes degrade accuracy by diverting the model into incorrect reasoning pathways
Concrete Example:
A standard reasoning model might correctly solve a math problem in 10 steps but continue generating 20 more steps of irrelevant verification or circular logic before outputting the final answer. Standard GRPO rewards this inefficient path equally to a concise one as long as the final answer is correct.
Key Novelty
Serial-Group Decaying-Reward Policy Optimization (S-GRPO)
- Constructs a 'serial group' from a single reasoning path by forcing early exits at random positions, rather than sampling multiple parallel paths like standard GRPO
- Applies a 'decaying reward strategy' where earlier correct answers receive higher rewards than later ones, explicitly incentivizing the model to reach the correct solution in fewer steps
Architecture
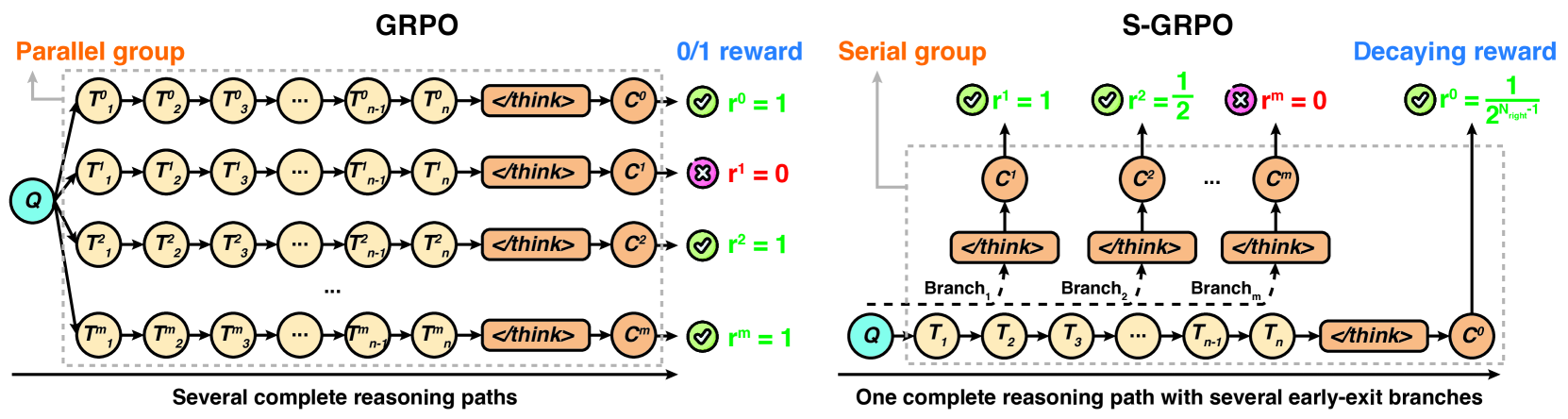
Contrast between standard GRPO (Parallel Group) and the proposed S-GRPO (Serial Group) frameworks.
Evaluation Highlights
- Reduces average token count by 35.4% to 61.1% across five benchmarks while maintaining or improving accuracy
- Achieves absolute accuracy improvements of 0.72% to 6.08% on datasets like GSM8K and MATH-500 using Qwen3 and Deepseek models
- Demonstrates synergistic improvement in both efficiency and accuracy, contradicting the typical trade-off between the two
Breakthrough Assessment
8/10
Offers a simple yet highly effective modification to standard RL post-training that solves a pervasive inefficiency ('overthinking') in current reasoning models without requiring complex architectural changes.
