📊 Experiments & Results
Evaluation Setup
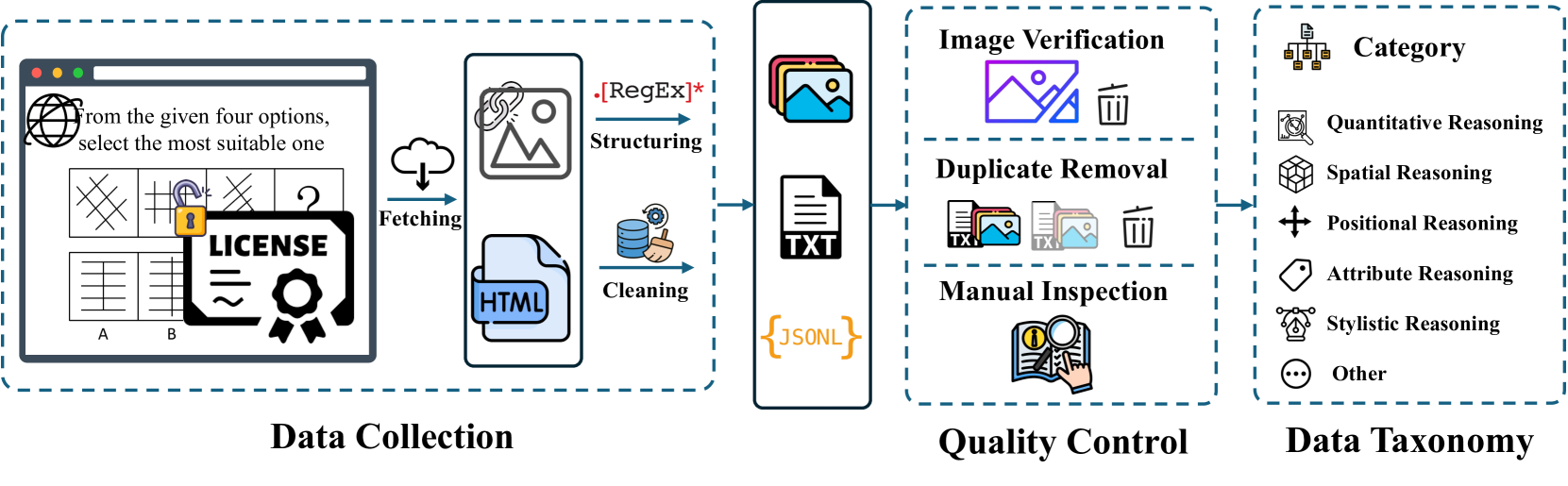
Zero-shot evaluation of pre-trained MLLMs and LLMs on 1,000 visual reasoning questions
Benchmarks:
- VisuLogic (Visual Logical Reasoning) [New]
Metrics:
- Accuracy (%)
- Statistical methodology: Not explicitly reported in the paper
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| Overall performance comparison showing that both LLMs (with captions) and MLLMs perform poorly, barely exceeding random chance. | ||||
| VisuLogic | Accuracy | 24.9 | 28.1 | +3.2 |
| VisuLogic | Accuracy | 51.4 | 28.1 | -23.3 |
| VisuLogic | Accuracy | 28.0 | 26.3 | -1.7 |
| Impact of Reinforcement Learning (RL) on visual reasoning performance. | ||||
| VisuLogic | Accuracy | 25.5 | 31.1 | +5.6 |
| VisuLogic | Accuracy | 26.0 | 28.0 | +2.0 |
Experiment Figures

Radar charts comparing error rates of LLMs, MLLMs, and Humans across the six reasoning categories (Quantitative, Spatial, Positional, Attribute, Stylistic, Other)
Qualitative examples of success and failure cases for different models (LLM vs MLLM vs RL-model)
Main Takeaways
- Text-only reasoning is insufficient: LLMs fed detailed captions perform near random chance, proving the benchmark requires genuine visual processing
- The 'Visual Reasoning Gap': Current SOTA MLLMs (GPT-4o, Gemini) are functionally equivalent to random guessers on deep visual logic tasks
- Reinforcement Learning is a promising path: RL fine-tuning yields the most significant performance gains, allowing models to learn multi-step visual deduction strategies
- Stylistic Reasoning is the hardest category: Models have error rates >75% (worse than random) on questions involving stylistic changes like overlays and contours