📊 Experiments & Results
Evaluation Setup
Zero-shot mathematical reasoning evaluation
Benchmarks:
- AMC23 (High school mathematics competition)
- AIME24 (Advanced invitational mathematics examination)
- MATH-500 (Challenging math problems)
- Minerva (Scientific and mathematical reasoning)
- OlympiadBench (Olympiad-level math and physics)
Metrics:
- Zero-shot pass@1 accuracy
- Statistical methodology: Not explicitly reported in the paper
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| Comparative analysis shows the proposed Open-RS models outperforming or matching significantly more expensive baselines on key math benchmarks. | ||||
| AIME24 | Accuracy (%) | 44.6 | 46.7 | +2.1 |
| AMC23 | Accuracy (%) | 63.0 | 80.0 | +17.0 |
| AIME24 | Accuracy (%) | 43.1 | 46.7 | +3.6 |
| Training Cost | USD ($) | 3629 | 42 | -3587 |
Experiment Figures
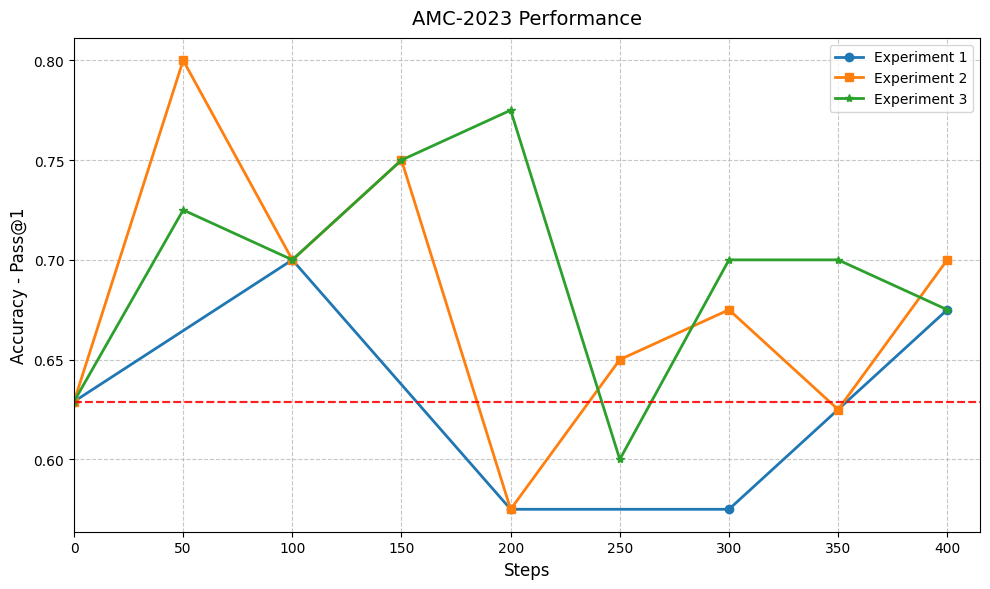
Accuracy curves on AMC23 and MATH-500 across training steps for three experiments
Completion length statistics during training
Main Takeaways
- Small LLMs can achieve competitive reasoning performance with minimal data (7k samples) if training stabilizes correctly
- Mixing problem difficulties (easy + hard) is crucial for training stability; using only hard problems (open-s1) leads to collapse
- Cosine-based length rewards effectively control output verbosity, preventing the model from hitting token limits, though language drift remains a challenge