📝 Paper Summary
Efficient Reasoning
Model Compression
Inference Acceleration
This survey categorizes efficient reasoning techniques into three directions—shortening reasoning chains, reducing model size via distillation/compression, and accelerating decoding—to mitigate the high computational costs of Large Reasoning Models.
Core Problem
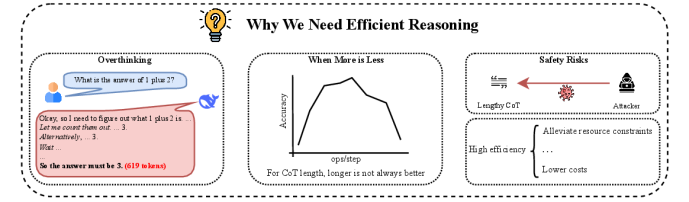
Large Reasoning Models (LRMs) generate excessively long Chain-of-Thoughts (CoTs) and rely on massive parameters, leading to high latency and computational redundancy without always guaranteeing better accuracy.
Why it matters:
- Reasoning models tend to 'overthink' simple problems (e.g., 600+ tokens for 1+2), wasting resources
- Real-world applications like embodied AI and autonomous driving require low-latency decision-making, which current slow-thinking models cannot provide
- Excessively long reasoning paths can accumulate errors and negatively impact final accuracy, challenging the assumption that longer CoTs are always better
Concrete Example:
Answering 'What is the answer of 1 plus 2?' requires 619 tokens from DeepSeek R1-685B. On the AIME 24 benchmark, the 1.5B model generates 15,513 tokens per query, creating massive overhead compared to standard LLMs.
Key Novelty
Taxonomy of Efficient Reasoning: Shorter, Smaller, Faster
- Shorter: Compressing lengthy CoTs into concise chains using RL with length penalties, variable-length SFT, or latent reasoning (thinking in hidden states)
- Smaller: Developing compact models with strong reasoning via knowledge distillation from larger teachers or model compression (quantization/pruning)
- Faster: Optimizing the decoding stage to reduce latency, including parallel decoding and efficient Test-Time Scaling (TTS) strategies
Architecture
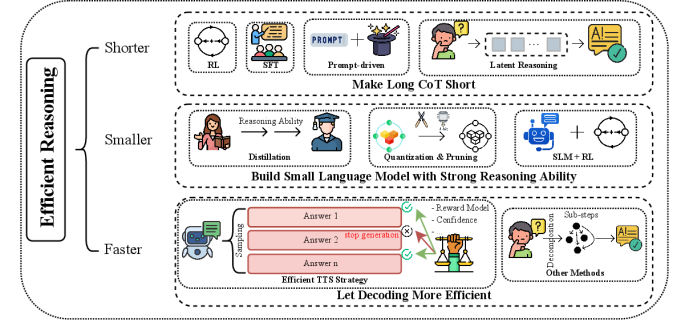
A taxonomy diagram categorizing efficient reasoning methods into three main branches: Shorter, Smaller, and Faster.
Evaluation Highlights
- DeepSeek R1-1.5B generates 15,513 tokens on average for AIME 24 tasks, highlighting extreme redundancy
- DeepSeek R1-32B reduces this to 10,024 tokens on AIME 24, suggesting larger models may reason more concisely but still incur high costs
- Quantization (e.g., 8-bit) is identified as nearly lossless for reasoning performance, whereas aggressive pruning significantly degrades reasoning capabilities
Breakthrough Assessment
9/10
Comprehensive survey establishing a clear 'Shorter, Smaller, Faster' taxonomy for a rapidly emerging field. Crucial for guiding future research in making reasoning models deployable.