📝 Paper Summary
Reasoning Segmentation
Multimodal Large Language Models (MLLMs)
Referring Segmentation
LISA enables multimodal LLMs to perform segmentation tasks requiring complex reasoning by mapping a special `<SEG>` token's embedding directly to a binary mask via an end-to-end trained decoder.
Core Problem
Existing perception systems rely on explicit instructions (e.g., 'segment the dog') and fail to interpret implicit user intentions or complex reasoning (e.g., 'segment the food high in Vitamin C').
Why it matters:
- Users in real-world scenarios (like robotics) prefer giving natural, implicit commands rather than step-by-step explicit instructions
- Current multimodal LLMs can reason about text but cannot output fine-grained visual masks, limiting their utility in vision-centric tasks
- Two-stage approaches that use an LLM to generate text tags for a separate segmentation model often fail due to information loss or disconnection
Concrete Example:
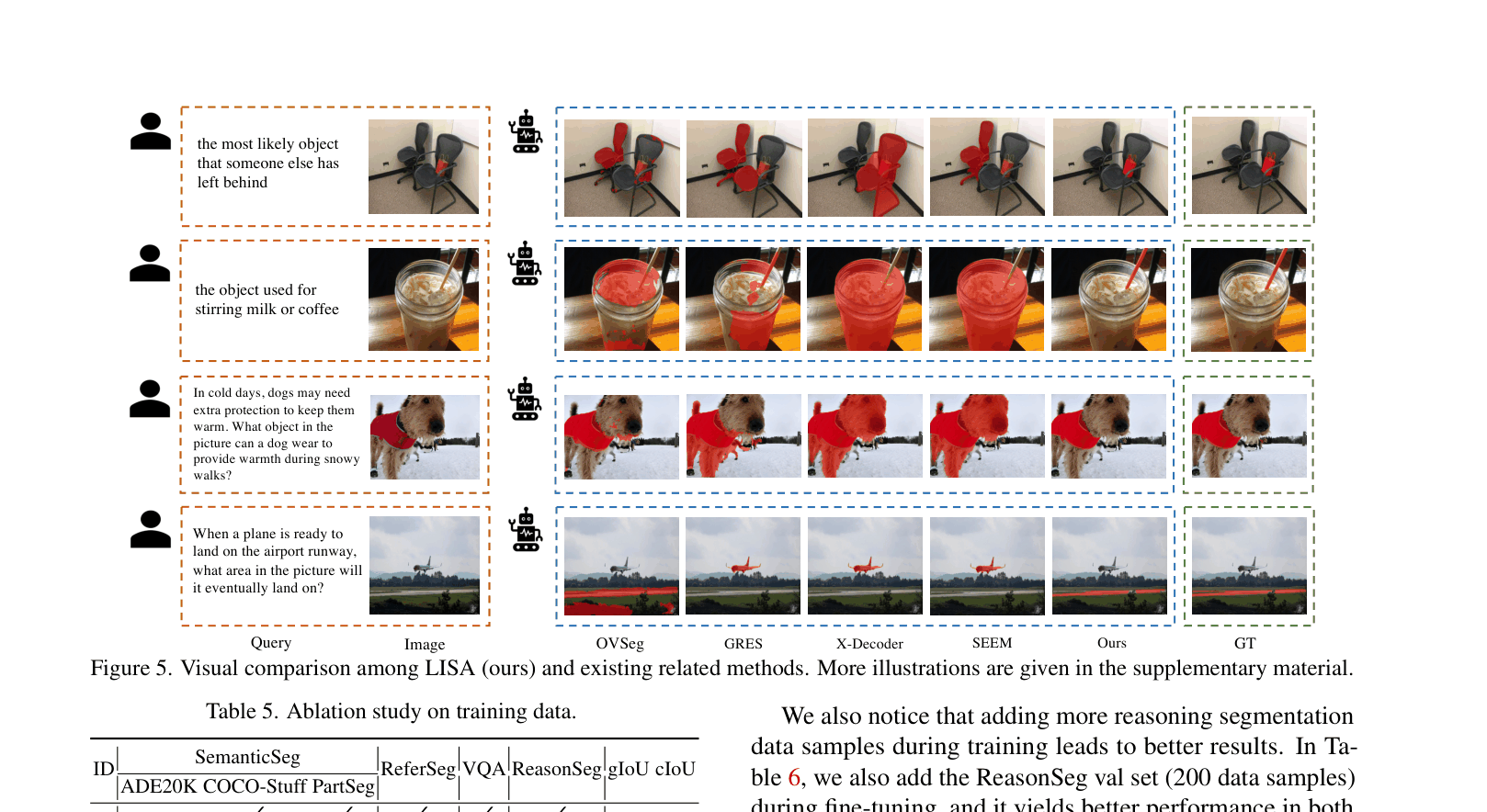
If a user asks 'Where can I throw away the rest of the food?' showing a kitchen, standard segmentors fail because they don't know what object matches that intent. LISA reasons that the target is a trash can and segments it directly.
Key Novelty
Embedding-as-Mask Paradigm
- Expands the LLM vocabulary with a `<SEG>` token; when the LLM generates this token, its hidden embedding is extracted
- This embedding acts as a dynamic instruction for a mask decoding module, bridging the gap between text generation and pixel-level segmentation
- Integrates reasoning capabilities of MLLMs with segmentation via end-to-end training, rather than using the LLM just to predict class names
Architecture
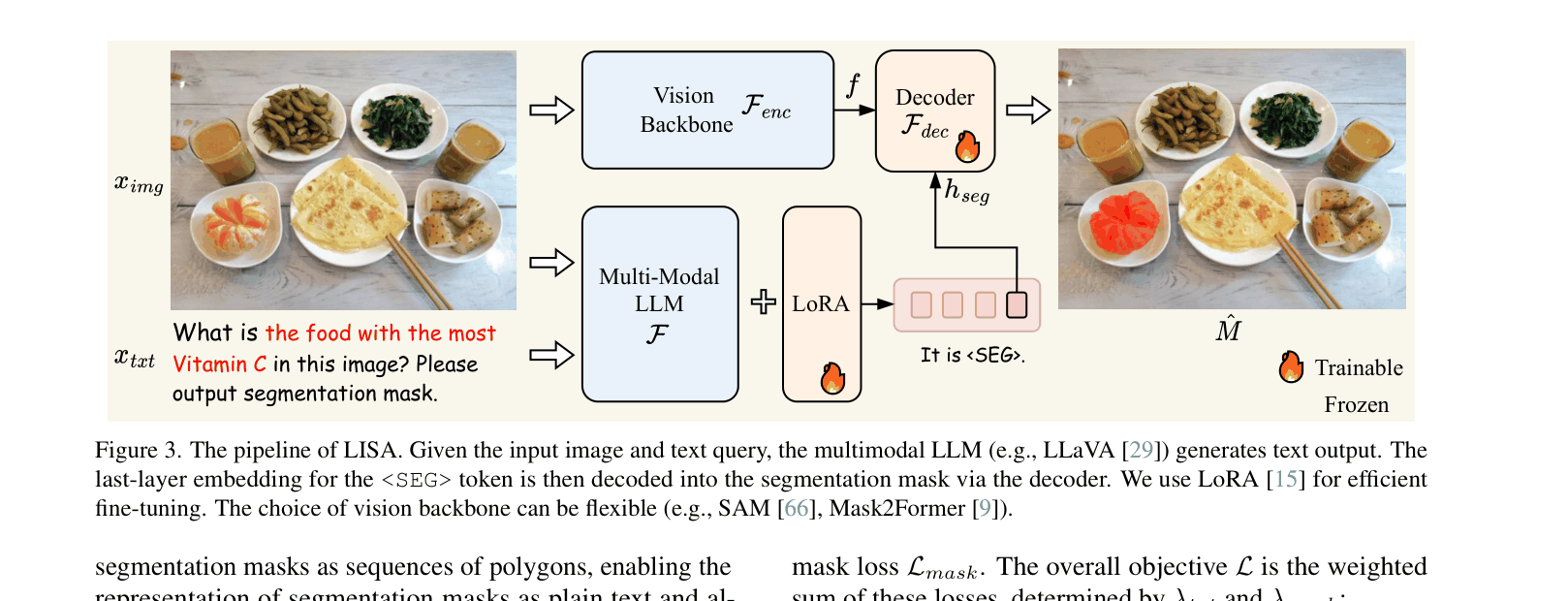
The LISA pipeline: Multimodal LLM processes image/text, outputs text and <SEG> token. <SEG> embedding is projected and fed to a Decoder along with visual features to produce a mask.
Evaluation Highlights
- LISA-13B (fine-tuned) achieves 63.2 gIoU on the new ReasonSeg benchmark, outperforming the specialized generalist model SEEM (25.6 gIoU) by over 37 points
- LISA-7B (fine-tuned) outperforms the two-stage pipeline 'LLaVA1.5 + OVSeg' (49.2 vs 39.7 gIoU) on overall reasoning segmentation, proving the value of end-to-end training
- Achieves strong zero-shot performance (36.6 gIoU with LISA-7B) on reasoning tasks despite being trained only on vanilla semantic/referring segmentation data
Breakthrough Assessment
9/10
Establishes a new task (Reasoning Segmentation) and a simple yet highly effective paradigm (embedding-as-mask) that unlocks pixel-level output for LLMs. The performance gap over baselines is massive.