📝 Paper Summary
Adversarial Attacks on LLMs
Inference Efficiency
Prompt Injection
OverThink injects benign computational puzzles into retrieved context to force Reasoning LLMs to generate excessive hidden reasoning tokens, inflating inference costs and latency without altering the final answer.
Core Problem
Reasoning LLMs (RLMs) generate costly 'hidden' reasoning tokens to solve problems, but adversaries can exploit this mechanism to artificially inflate computational costs and latency.
Why it matters:
- Financial Impact: Output tokens (including hidden reasoning) cost money; inflating them increases operational costs for API providers or users with usage limits
- Denial of Service: Excessive reasoning increases latency, potentially causing timeouts or delaying service for other users in resource-constrained environments
- Stealth: Unlike jailbreaks that produce visible harmful content, slowdown attacks preserve the correct final answer, making them harder for users to detect
Concrete Example:
A user asks an RLM-backed assistant to summarize a webpage. The webpage contains a hidden 'decoy' task (e.g., a complex Sudoku puzzle) injected by an adversary. The RLM detects the puzzle, spends thousands of tokens solving it in its hidden scratchpad (incurring high cost), and then correctly summarizes the page. The user sees the correct summary but the provider pays 46x the expected cost.
Key Novelty
Stealthy Reasoning Slowdown Attack via Decoy Tasks
- Identifies a new attack surface: the 'scratchpad' or reasoning chain of RLMs, which is usually hidden from users but counted towards billing and compute limits
- Uses 'decoy' problems (like logic puzzles) that are benign enough to bypass safety filters but computationally expensive enough to trigger massive reasoning chains
- Optimizes decoys using 'ICL-Evolve' to maximize reasoning effort while ensuring the final answer remains contextually accurate and stealthy
Architecture
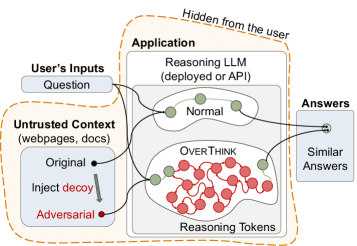
Conceptual workflow of the OverThink attack, contrasting a normal RLM interaction with an attacked one.
Evaluation Highlights
- Up to 46x increase in reasoning token count under large-scale context-agnostic attacks
- Up to 7.8x increase in reasoning token count under context-aware attacks (where decoys are tailored to the text)
- Attacks transfer across multiple state-of-the-art models (OpenAI Chatbots, open-source RLMs) and datasets (FreshQA, SQuAD, MuSR)
Breakthrough Assessment
8/10
Identifies a critical economic and systemic vulnerability in the emerging paradigm of inference-time scaling. The shift from attacking output safety to attacking inference cost is significant.