📝 Paper Summary
LLM Pre-training
Data Curation
Data Mixing
Organizing pre-training data by semantic topics rather than data sources consistently improves LLM performance across multiple mixing algorithms by creating a better optimization landscape.
Core Problem
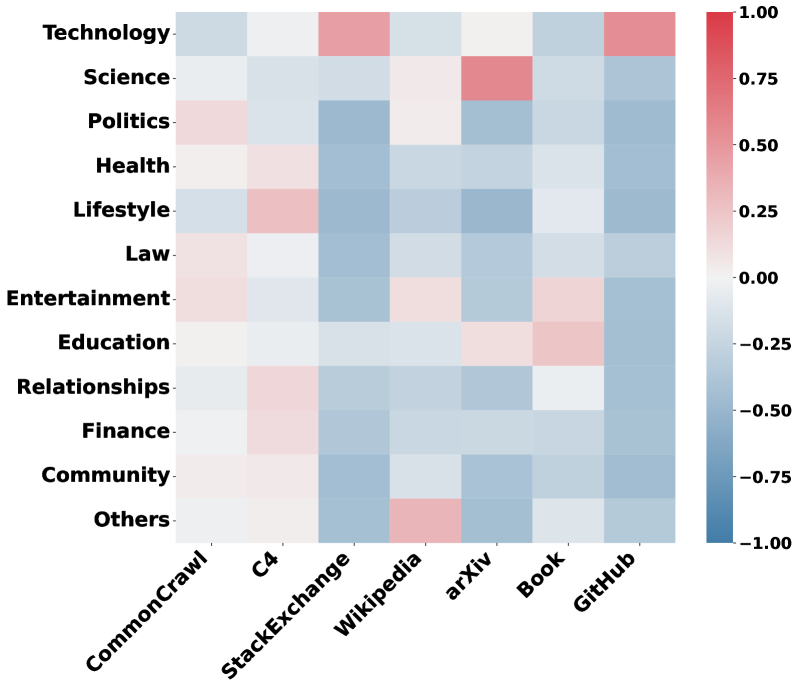
Current data mixing strategies rely on coarse 'sources' (e.g., CommonCrawl, GitHub) which contain heterogeneous topics, failing to capture semantic nuances needed for optimal training.
Why it matters:
- Single sources like CommonCrawl contain diverse topics (Science, Politics) with varying relevance to downstream tasks, making source-level mixing inefficient.
- Modern web-crawled datasets (FineWeb, DCLM) often lack meaningful source divisions, rendering source-based mixing obsolete.
- Existing semantic sorting methods either require heavy human supervision (WebOrganizer) or lack scalability/labeling (unsupervised clustering).
Concrete Example:
A 'Science' topic appears across arXiv (high quality) and CommonCrawl (noisy), while CommonCrawl also contains 'Entertainment'. Source-based mixing treats all CommonCrawl data identically, preventing the model from specifically upweighting high-value scientific content regardless of where it comes from.
Key Novelty
Topic-based Data Mixing via Scalable Taxonomy
- Replace source labels (e.g., 'Wikipedia') with semantic topic labels (e.g., 'Science', 'Law') generated via a scalable pipeline of clustering, LLM summarization, and supervised classification.
- Apply standard data mixing algorithms (DoReMi, RegMix) to these semantic distributions instead of source distributions to compute optimal pre-training weights.
Architecture
Multi-stage Topic Extraction Pipeline
Evaluation Highlights
- +1.90 accuracy gain on Reading Comprehension tasks using Temperature-Topic mixing compared to source-based mixing (1.3B model).
- PerfRe-Topic (topic-based reweighting) achieves highest average score of 45.23, outperforming source-based PerfRe (44.63) and advanced methods like DoReMi-Topic (45.00).
- Scaling to 3.3B parameters increases the advantage of topic-based mixing over source-based mixing from 0.5 to 0.7 average points.
Breakthrough Assessment
7/10
Provides the first comprehensive empirical evidence that semantic partitioning is superior to source partitioning for data mixing. While the mixing algorithms themselves are standard, the pipeline and findings on semantic organization are significant for future data curation.