📊 Experiments & Results
Evaluation Setup
Few-shot learning (training from scratch on ~1000 examples) on logical reasoning tasks.
Benchmarks:
- ARC-AGI (Inductive reasoning / Visual puzzles)
- Sudoku-Extreme (Constraint satisfaction / Backtracking search)
- 30x30 Maze (Optimal pathfinding / Breadth-First Search)
Metrics:
- Accuracy (%)
- Statistical methodology: Not explicitly reported in the paper
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| ARC-AGI Benchmark: HRM significantly outperforms massive state-of-the-art LLMs despite having orders of magnitude fewer parameters and training data. | ||||
| ARC-AGI | Accuracy | 34.5 | 40.3 | +5.8 |
| ARC-AGI | Accuracy | 21.2 | 40.3 | +19.1 |
| Complex Reasoning Tasks: HRM solves hard search problems where standard CoT approaches fail. | ||||
| Sudoku-Extreme Full | Accuracy | 0 | 98 | +98 |
| 30x30 Maze (Optimal Path) | Accuracy | 0 | 100 | +100 |
Experiment Figures
Bar chart comparing HRM performance on ARC-AGI against major LLMs (o3-mini, Claude 3.7, GPT-4o, etc.).
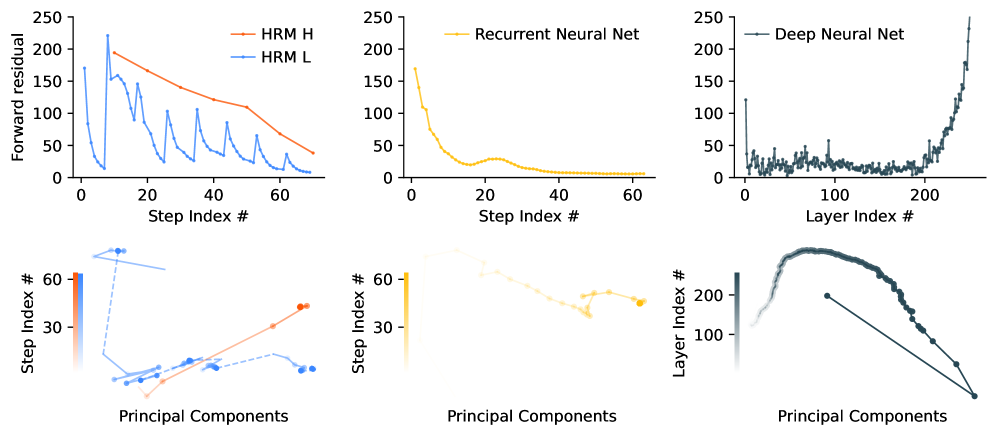
Analysis of 'Forward Residual' (activity level) over timesteps for HRM vs Standard RNN.
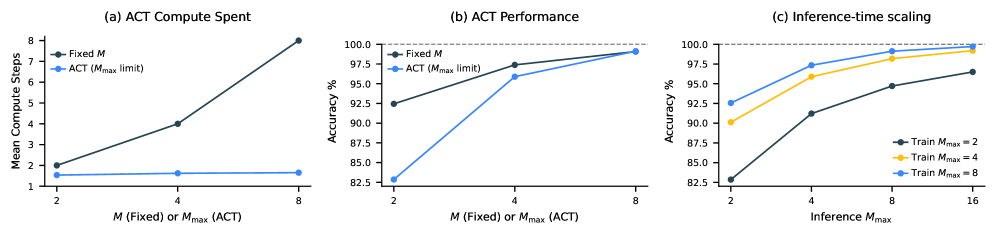
Effect of Adaptive Computational Time (ACT) and Inference-time scaling.
Main Takeaways
- Effective depth is critical: Increasing the computational depth (number of recurrence steps) dramatically improves performance on reasoning tasks, whereas simply scaling model width (parameters) yields diminishing returns.
- Latent reasoning works: Complex multi-step reasoning can be performed efficiently in hidden states without externalizing thought into tokens (CoT), saving massive compute.
- Inference-time scaling: The model allows increasing the maximum computation steps (M_max) at test time to boost performance further without retraining.
- Data efficiency: HRM achieves these results with only ~1000 training examples, suggesting the inductive bias of hierarchical recurrence is far better suited for reasoning than standard Transformer architectures.