📊 Experiments & Results
Evaluation Setup
Zero-shot evaluation of 18 LALMs on the MMAU benchmark
Benchmarks:
- MMAU (Multimodal Audio Question Answering) [New]
Metrics:
- Micro-averaged Accuracy
- Statistical methodology: Not explicitly reported in the paper
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| Comparison of top proprietary and open-source models against human performance on MMAU. | ||||
| MMAU | Accuracy | 81.85 | 52.97 | -28.88 |
| MMAU | Accuracy | 52.97 | 52.50 | -0.47 |
| MMAU | Accuracy | 52.97 | 59.08 | +6.11 |
| MMAU | Accuracy | 52.50 | 33.47 | -19.03 |
Experiment Figures
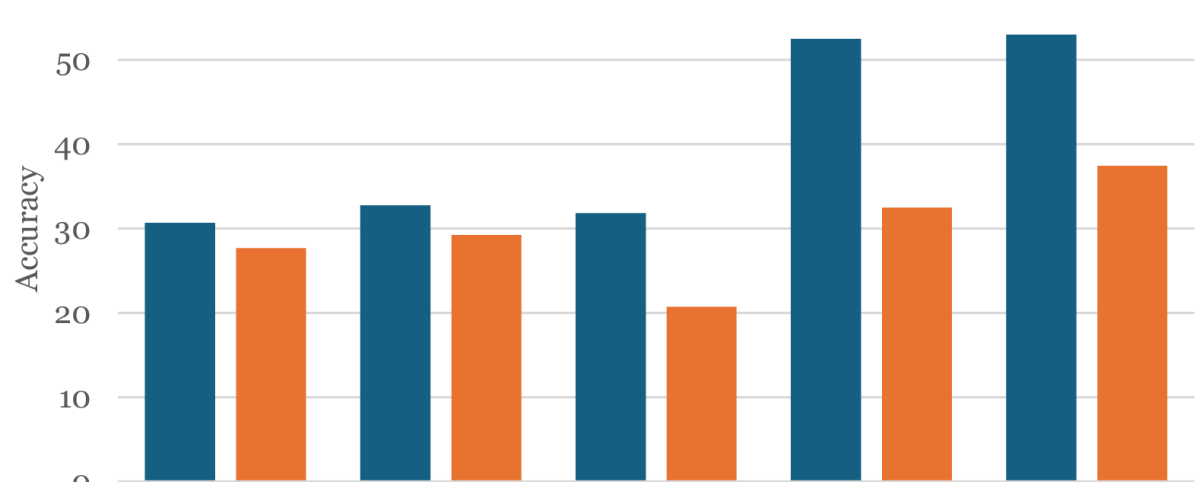
Performance drop when audio is replaced by Gaussian noise vs. original audio

Distribution of error types for Qwen2-Audio and Gemini Pro 1.5
Main Takeaways
- There is a significant 'reasoning gap': models struggle most with complex reasoning tasks compared to basic information extraction.
- Models perform best on Environmental Sounds and worst on Speech Reasoning, suggesting that while ASR is mature, reasoning *about* speech (e.g., role mapping, intent) is unsolved.
- Cascaded systems (Captioning -> LLM) currently outperform end-to-end LALMs, implying that text-based reasoning (LLMs) is ahead of multimodal integration.
- Open-source models (Qwen2-Audio) are effectively on par with proprietary models (Gemini Pro), democratizing advanced audio research.