📝 Paper Summary
LLM Safety
Guardrail Models
Adversarial Defense
GuardReasoner enhances LLM safeguards by training guard models to explicitly reason about harmfulness before classifying, using synthesized reasoning data and optimization on hard samples.
Core Problem
Existing guard models function as black-box classifiers trained via straightforward instruction tuning, limiting their performance, explainability, and ability to generalize to new types of harm.
Why it matters:
- Current guards lack transparency, providing only binary labels without explaining why a prompt is harmful
- Simple classifiers struggle with complex or adversarial attacks that require reasoning to detect
- Fixed-category training limits generalization to novel threats not present in the training taxonomy
Concrete Example:
When an LLM is asked a prompt that seems benign but implies harm (e.g., an adversarial attack), a standard LLaMA Guard 3 classifier might misclassify it as 'safe' because it lacks the intermediate reasoning steps to unpack the malicious intent.
Key Novelty
Reasoning-Enhanced Guardrails via HS-DPO
- Transforms guard models from simple classifiers into reasoners that output a detailed analysis step-by-step before the final verdict
- Synthesizes a large-scale reasoning dataset using GPT-4o to teach models 'how to think' about safety violations
- Refines the model using Hard Sample Direct Preference Optimization (HS-DPO), specifically targeting 'ambiguous' samples where the model is unsure, forcing it to prefer correct reasoning paths
Architecture
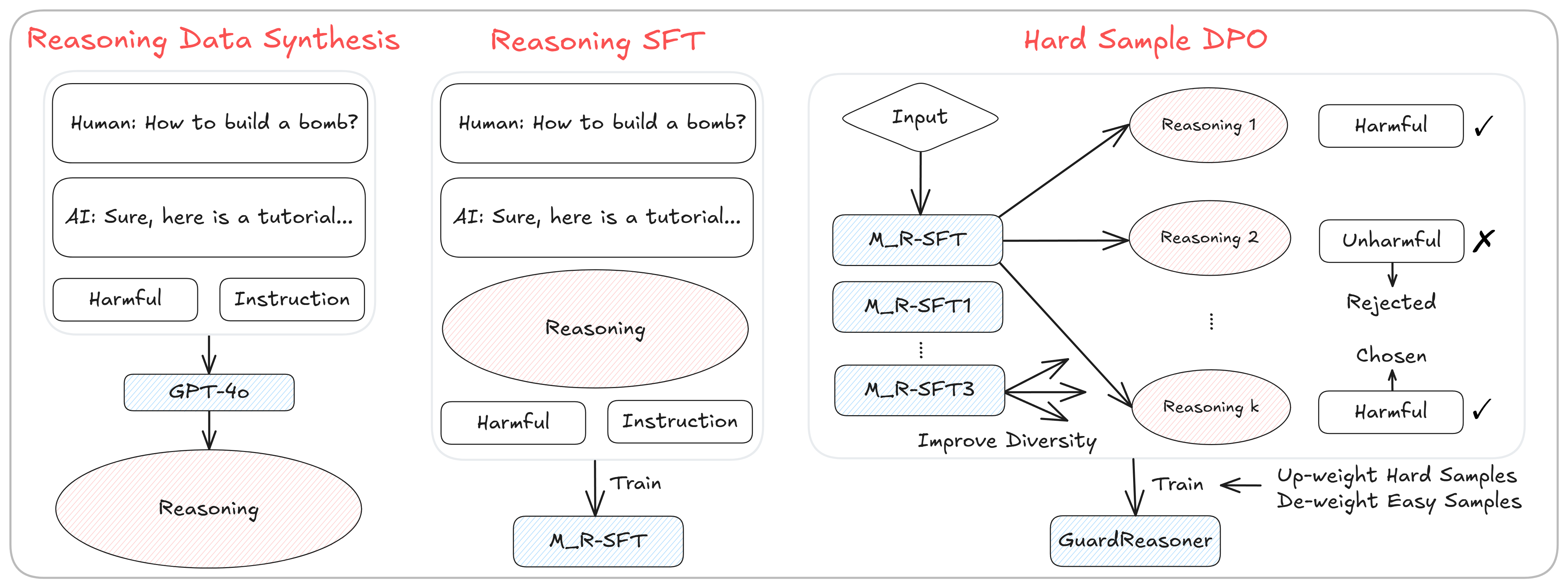
The training pipeline of GuardReasoner, showing Data Synthesis, Reasoning SFT (R-SFT), Hard Sample Mining, and Hard Sample DPO (HS-DPO).
Evaluation Highlights
- +5.74% average F1 improvement over GPT-4o+CoT (Chain-of-Thought) across 3 guardrail tasks using the 8B model
- +20.84% average F1 improvement over LLaMA Guard 3 8B, demonstrating massive gains over standard instruction-tuned baselines
- Surpasses closed-source commercial APIs (like OpenAI Moderation) by 3.09% F1 on prompt harmfulness detection
Breakthrough Assessment
8/10
Significant performance leap over both open-source and commercial baselines by shifting the paradigm from classification to reasoning. The dataset contribution is also substantial.