📝 Paper Summary
Efficient Large Language Models
Reasoning Models
Neural Architecture Search (NAS)
Llama-Nemotron optimizes Llama 3 baselines via neural architecture search and large-scale reinforcement learning to create open reasoning models that surpass DeepSeek-R1 in efficiency and performance.
Core Problem
State-of-the-art reasoning models require massive compute at inference time (scaling laws) and lack user control over when to expend this compute.
Why it matters:
- Inference latency and memory costs are the primary bottlenecks for deploying intelligent agentic pipelines
- Users cannot currently toggle 'deep thinking' on or off within a single model, leading to unnecessarily verbose and expensive responses for simple queries
- Existing open-weights reasoning models (like 671B MoE) are often too large for single-node deployment in enterprise environments
Concrete Example:
For a simple query like 'Hello', a standard reasoning model might generate a long Chain-of-Thought (CoT) trace, wasting tokens. Llama-Nemotron allows a system prompt 'detailed thinking off' to bypass this, while 'detailed thinking on' activates deep reasoning for complex math.
Key Novelty
Inference-Optimized Reasoning via Puzzle NAS and FFN Fusion
- Uses Neural Architecture Search (NAS) to selectively remove attention layers and compress Feed-Forward Networks (FFNs) from Llama 3 baselines, optimizing for hardware constraints
- Introduces FFN Fusion to merge consecutive feed-forward layers resulting from attention removal, allowing them to execute in parallel and reducing latency
- Implements a 'Reasoning Toggle' via training on paired data, allowing dynamic switching between standard chat and heavy reasoning modes at inference time
Architecture
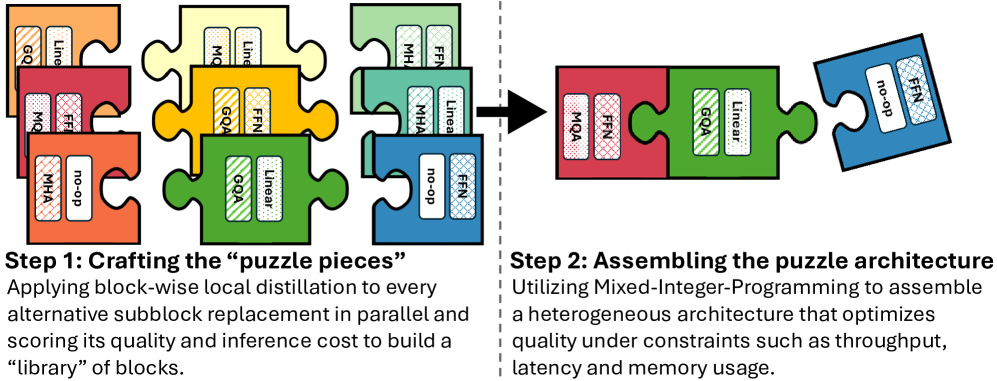
The Puzzle NAS process transforming a standard Llama block into efficient variants
Evaluation Highlights
- LN-Super (49B) achieves 5x throughput speedup over Llama 3.3-70B-Instruct at batch size 256 on a single H100 GPU
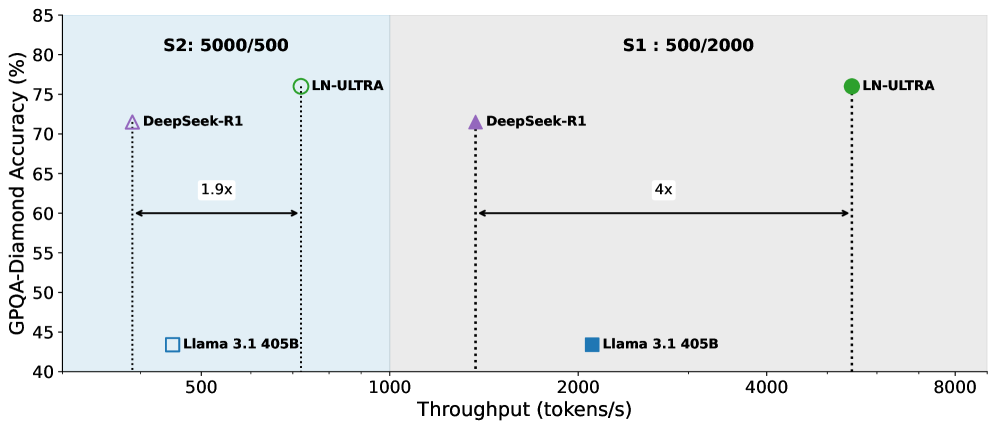
- LN-Ultra (253B) achieves 1.71x latency improvement over Llama 3.1-405B-Instruct while fitting on a single 8xH100 node
- LN-Ultra outperforms DeepSeek-R1 and Llama-3.1-405B-Instruct on GPQA-Diamond accuracy while delivering higher token throughput
Breakthrough Assessment
9/10
Significant engineering breakthrough combining aggressive architecture search/compression with state-of-the-art reasoning RL. Delivers a DeepSeek-R1 competitor that is far more practical for deployment.