📝 Paper Summary
AI Safety
Alignment
Chain-of-Thought Reasoning
Deliberative Alignment trains language models to explicitly reason about safety specifications within a hidden chain-of-thought before answering, replacing implicit pattern matching with verifiable rule adherence.
Core Problem
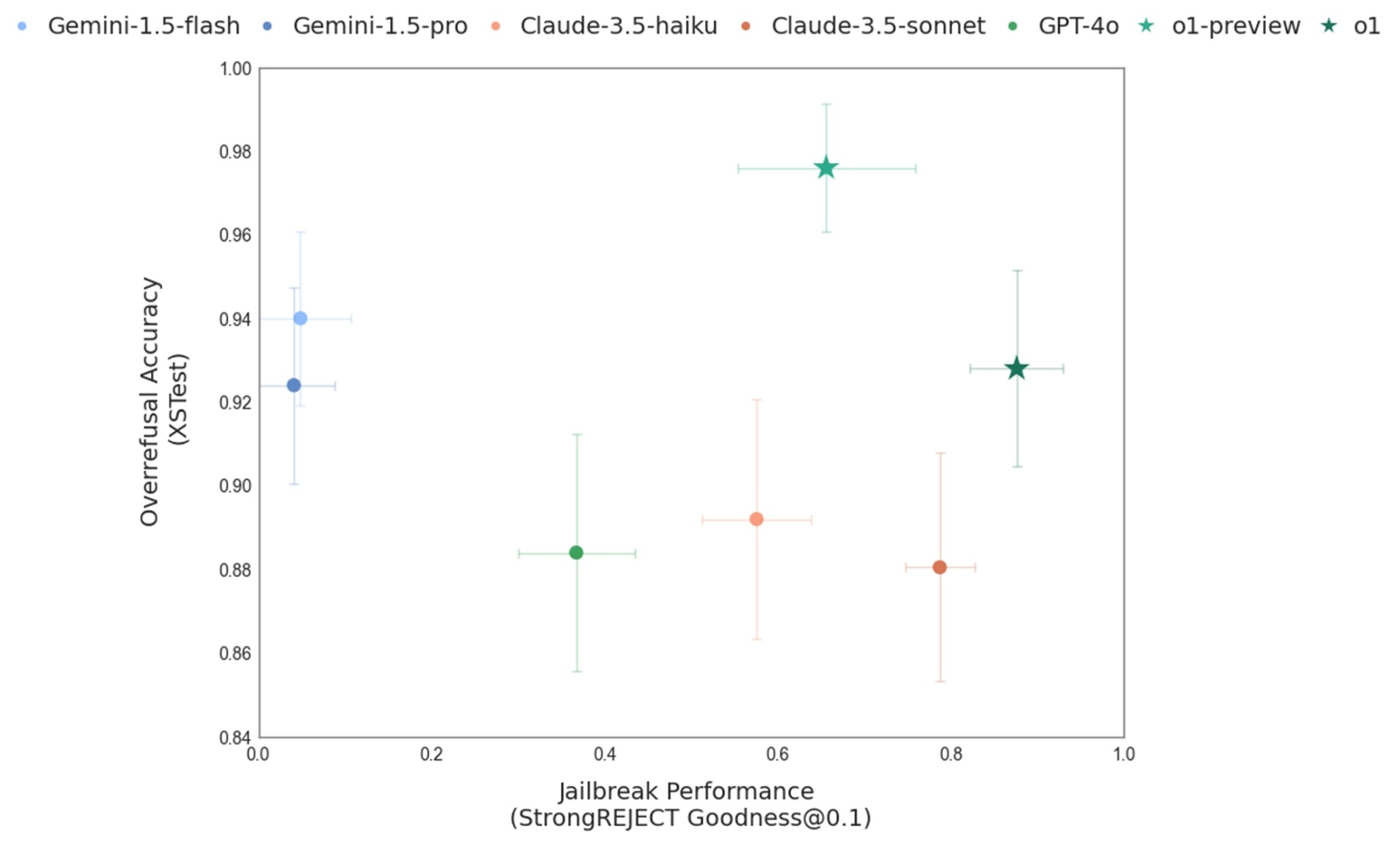
Standard safety training relies on implicit pattern matching and instant responses, causing models to fail on complex edge cases, succumb to jailbreaks, or overly refuse benign requests.
Why it matters:
- Models often refuse legitimate requests (over-refusal) because they rely on shallow heuristics rather than understanding the nuance of safety rules
- Implicit learning is data-inefficient and fails to generalize to new adversarial attacks (jailbreaks) or unfamiliar scenarios
- Relying on human labels for every safety case scales poorly as model capabilities increase beyond human intuition
Concrete Example:
A model trained via standard RLHF might instantly refuse a request for 'a story about a robbery' due to keyword matching, whereas a deliberative model would reason: 'The policy allows fictional depictions of crime if they don't provide instructional details,' and then comply.
Key Novelty
Deliberative Alignment (Reasoning-based Safety)
- Teaches the model to 'think before it speaks' by generating a hidden Chain-of-Thought (CoT) that explicitly cites and checks relevant safety policies
- Uses Context Distillation to internalize the safety policy: the model is trained to recall and apply the rules without needing them in the prompt at inference time
- Utilizes a synthetic data pipeline where a 'Judge' model (with access to the policy) evaluates reasoning, removing the need for human safety labels
Architecture
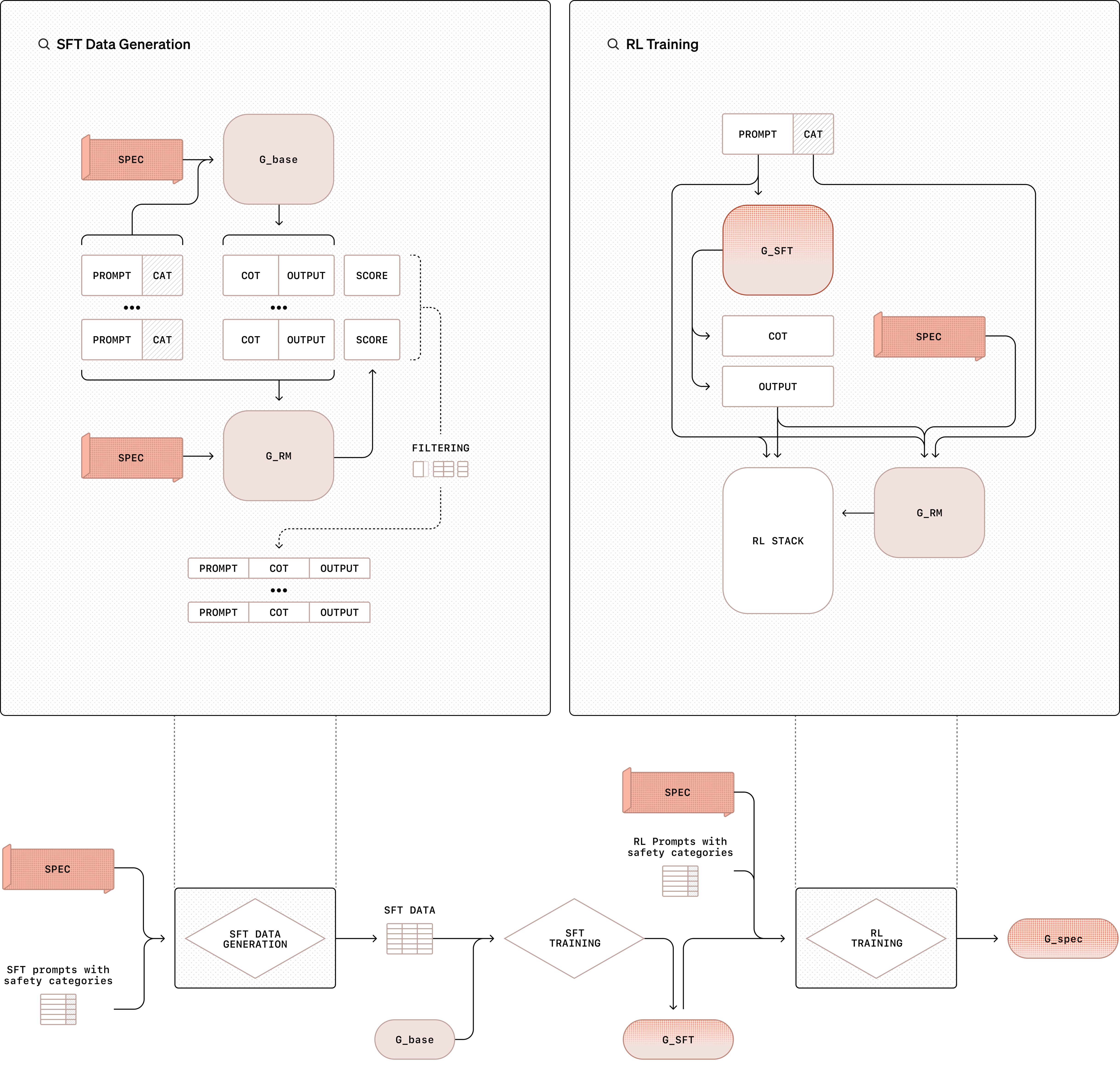
The Deliberative Alignment training pipeline
Breakthrough Assessment
8/10
Significant shift from implicit safety alignment to explicit reasoning-based alignment. Claims to solve the trade-off between safety and helpfulness (Pareto improvement) without human labels.