📝 Paper Summary
Chain-of-Thought (CoT) Reasoning
Preference Optimization
Iterative Training
Iterative Reasoning Preference Optimization (Iterative RPO) improves LLM reasoning by repeatedly generating Chain-of-Thought candidates, constructing preference pairs based on answer correctness, and training with a combined DPO and NLL objective.
Core Problem
Standard iterative preference optimization methods (like Self-Rewarding LLMs or SPIN) improve general instruction following but often fail to improve, or even degrade, performance on complex reasoning tasks.
Why it matters:
- Reasoning tasks require generating correct intermediate steps (Chain-of-Thought), which general alignment methods often overlook
- Existing iterative methods for reasoning (like STaR) rely on Supervised Fine-Tuning (SFT), missing the signal provided by negative/incorrect reasoning paths
- Verifying the correctness of reasoning steps is difficult without human annotation, limiting the scalability of methods that require step-by-step rewards
Concrete Example:
In GSM8K, a model might generate a reasoning chain that leads to the wrong answer. Standard SFT only trains on the correct 'gold' chain. Iterative RPO uses the incorrect chain as a 'loser' in a preference pair against a correct 'winner', explicitly teaching the model what *not* to do.
Key Novelty
Iterative Reasoning Preference Optimization (Iterative RPO)
- Generates multiple Chain-of-Thought (CoT) candidates per prompt using the current model
- Constructs preference pairs where 'winners' result in the correct final answer (verified against gold labels) and 'losers' result in incorrect answers
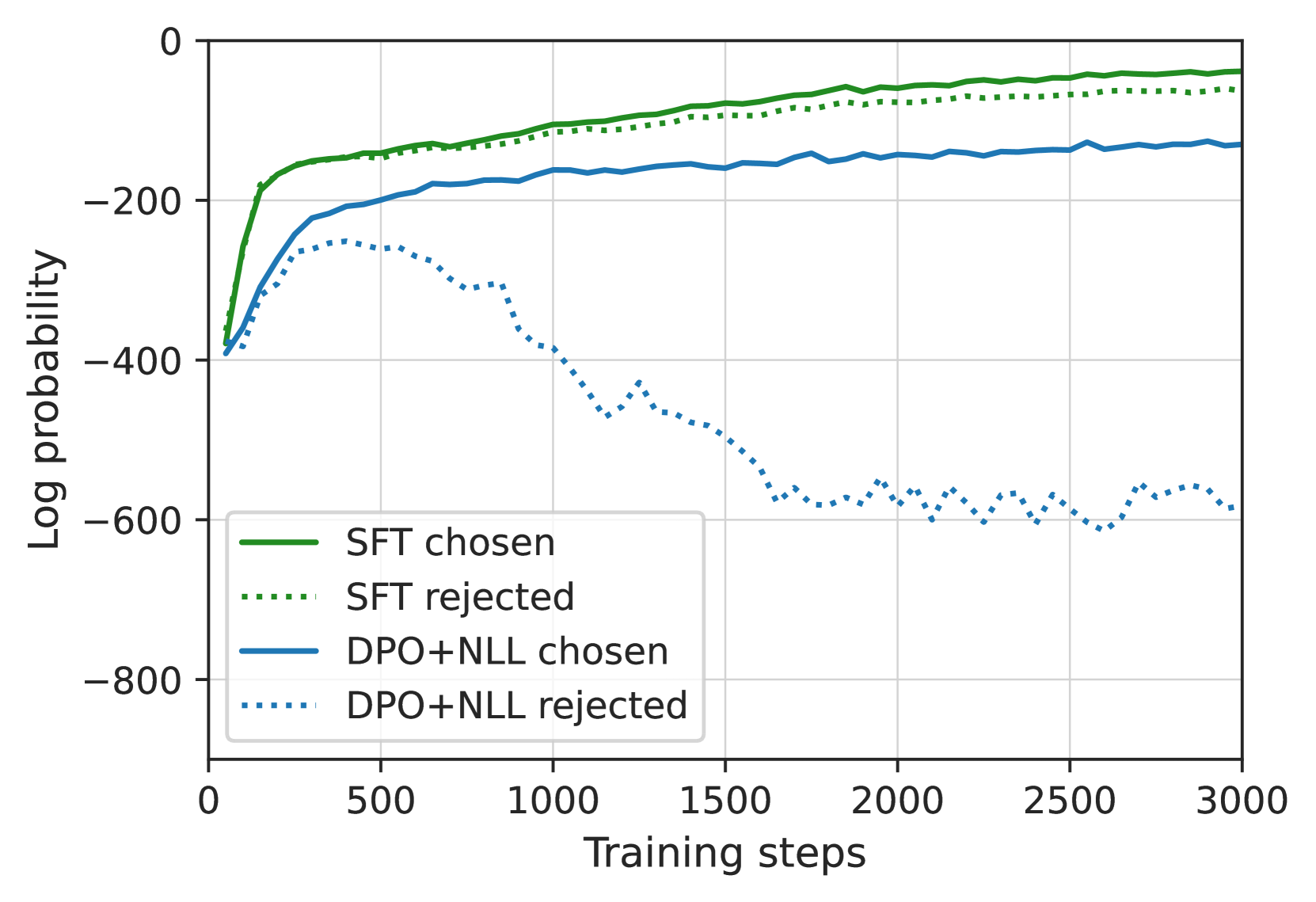
- Trains the next iteration's model using a specific loss combining DPO (Direct Preference Optimization) with a Negative Log-Likelihood (NLL) term on the winning response to prevent probability degradation
Architecture
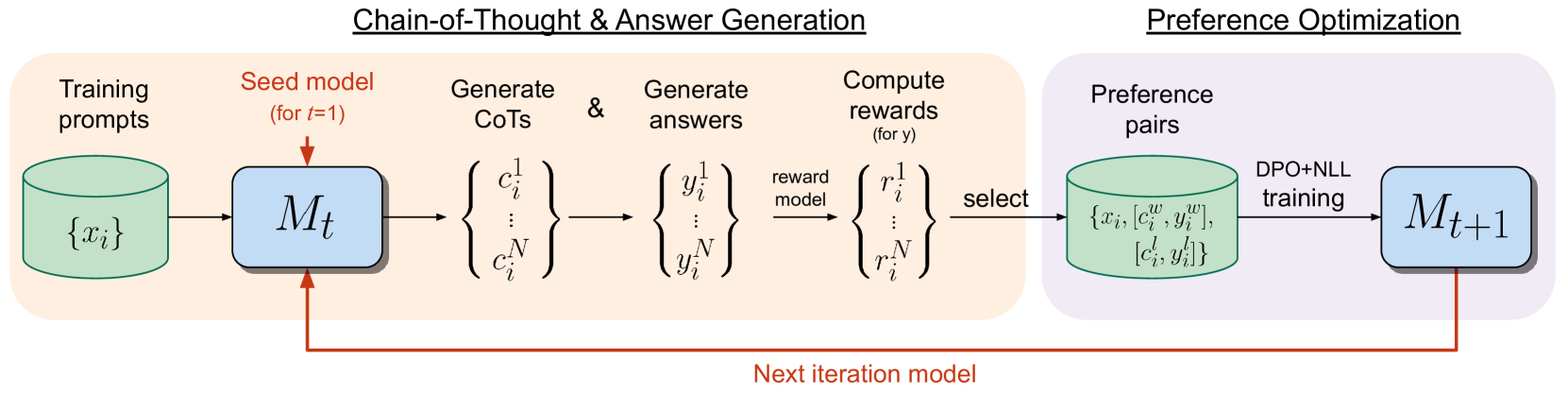
The iterative training loop of Iterative RPO.
Evaluation Highlights
- Improves Llama-2-70B-Chat zero-shot accuracy on GSM8K from 55.6% to 81.6% (greedy decoding)
- Achieves 88.7% accuracy on GSM8K with majority voting (32 samples), up from 70.7% baseline
- Increases accuracy on ARC-Challenge from 77.8% to 86.7% without using the ARC training corpus
Breakthrough Assessment
8/10
Significant gains on established reasoning benchmarks (GSM8K, MATH) using only training set prompts. The generated improvements are substantial (+26% on GSM8K) and the method is simpler than concurrent approaches requiring separate reward models.