📊 Experiments & Results
Evaluation Setup
Mathematical reasoning evaluation using symbolic variants of GSM8K
Benchmarks:
- GSM-Symbolic (Grade School Math (Variable Instantiations)) [New]
- GSM-NoOp (Grade School Math with Irrelevant Context) [New]
- GSM-P1 / GSM-P2 (Grade School Math with Increased Complexity (Plus 1/2 Clauses)) [New]
Metrics:
- Accuracy (Standard Pass@1)
- Performance Variance (across instantiations)
- Performance Drop (Delta between GSM8K and variants)
- Statistical methodology: Not explicitly reported in the paper
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| Experiments measuring performance variance across different numerical instantiations of the same logical templates. | ||||
| GSM-Symbolic | Performance Gap (Best vs Worst Instantiation) | 0 | 15 | +15 |
| GSM-Symbolic | Performance Gap (Best vs Worst Instantiation) | 0 | 12 | +12 |
| Experiments on the GSM-NoOp dataset, measuring the impact of adding irrelevant information. | ||||
| GSM-NoOp | Performance Drop (Relative) | 0 | -65 | -65 |
Experiment Figures
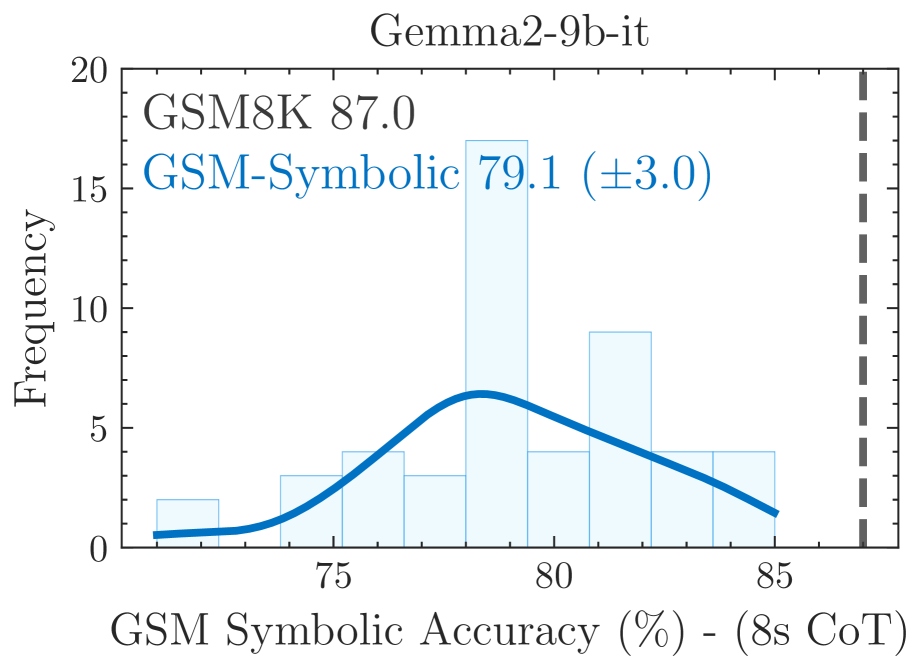
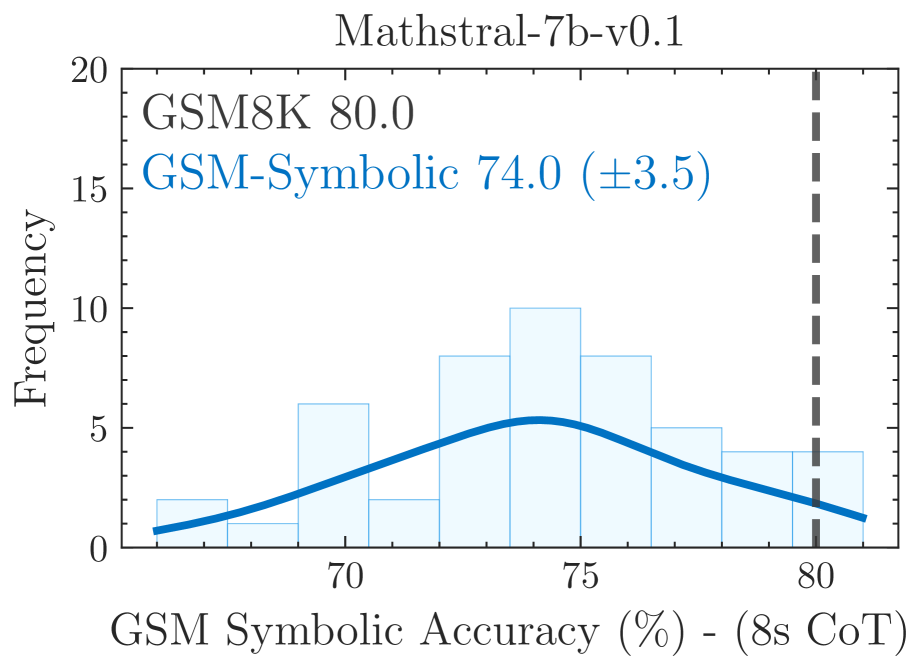
Distribution of accuracy for various models across 50 generated GSM-Symbolic datasets
Performance comparison between GSM-Symbolic and GSM-NoOp (with irrelevant clauses)
Main Takeaways
- LLMs exhibit significant performance variance (12-15%) on GSM-Symbolic when only numerical values are changed, suggesting they do not possess stable logical reasoning
- Performance consistently degrades as the number of clauses increases (GSM-P1, GSM-P2), with variance increasing simultaneously
- Models show catastrophic failure on GSM-NoOp (up to 65% drop), often converting irrelevant statements (e.g., 'discount') into mathematical operations (e.g., multiplication) blindly
- Providing 8-shot examples of the *same* question (NoOp-Symb) does not recover performance on GSM-NoOp, indicating the issue is deeper than in-context learning can fix